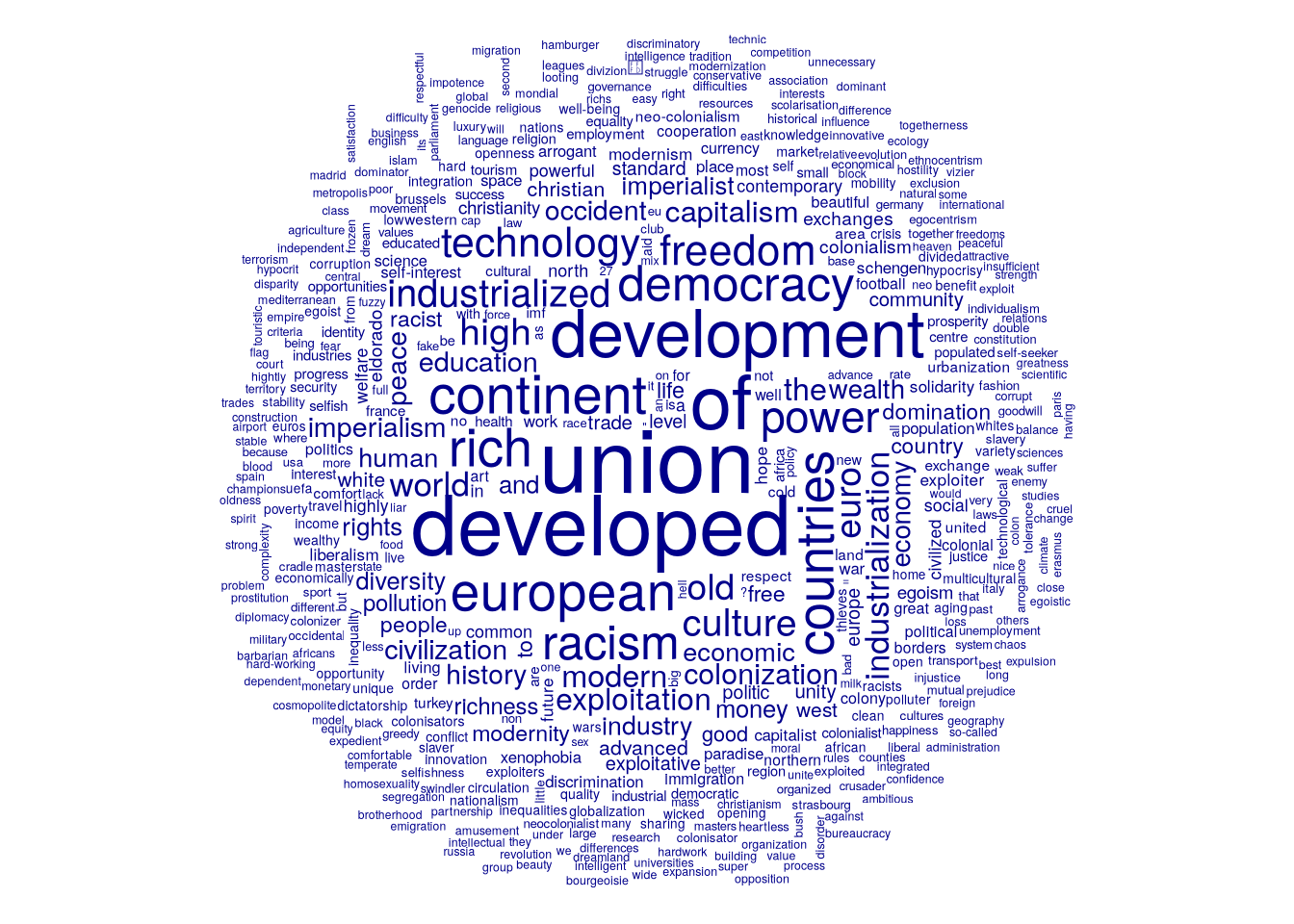
Dans l’approche proposée par l’école française d’analyse de données (Beaudouin, 2016), le principe général de la statistique textuelle est de mettre les méthodes de l’analyse des données - des méthodes généralistes de tableaux de données (analyses factorielles, classifications) - au service d’une analyse exploratoire des textes.
Le principe est toujours le même:
construction d’un tableau de données : tableau lexical entier (TLE) et/ou transformation de ce tableau (tableau lexical agrégé, TLA).
analyse statistique, en commençant généralement par une analyse univariée (analyse du lexique), puis bivariée (test statistique), puis multivariées (analyse factorielles et classifications).
Dans cette séance on présentera donc une en quelque sorte “analyse canonique”, telle que présente dans des publications historiques utilisant la statistique textuelle en sciences sociales francophones (Guérin-Pace, 1997).
On suppose que le corpus est construit (cf. séance 1).
Les tableaux et analyses proposées ici portent sur des calculs de fréquences de mots. D’autres tableaux sont possibles (co-fréquences saisies par les cooccurrences).
3.0.2 Données de l’exercice
La première partie de la séance portera sur une version simplifiée de données d’enquête.
3.0.2.1 L’enquête Eurobroadmap “Mental Maps of Students”
L’enquête Eurobroadmap « Mental Maps of students » fut menée dans le cadre du projet de recherche Eurobroadmap du 7e PCRD de la Commission Européenne (Beauguitte et al., 2012). Ce projet de recherche européen avait pour objectif de saisir la place de l’Europe dans le monde à travers différentes thématiques (politique, économique, etc.).
Cette enquête s’intéressait aux représentations de l’Europe dans le monde du point de vue d’étudiants en fin de premier cycle universitaire (niveau L3). Elle reposait sur la passation d’un questionnaire auto-administré auprès de 10 000 étudiants de niveau Licence 3 répartis dans 18 pays du Monde entre juillet 2009 et 2010. On travaillera ici sur une version réduite de la base de données (sélection de pays d’enquête et de variables).
Les données textuelles correspondent au module D du questionnaire: une question ouverte, proposée dans la langue nationale du pays d’enquête; recourant à la technique des mots associés : « Quels sont pour vous les mots que vous associez le plus à “Europe”. Choisissez 5 mots au maximum » (pour plus d’information sur l’analyse lexicale de cette enquête voir Brennetot et al., 2013).
Seule une sélection de quatre pays d’étude disponibles dans la base initiale a été retenue pour simplifier l’exercice.
3.0.3 Préparation des données et de l’espace de travail
3.0.3.1 import des données et selection des pays d’étude
# chargement du tableauEBM_df <-read.csv("data/tabquest3_V9.csv",sep=c(";"),fileEncoding ="UTF-8")# impression de la liste des Etatsprint(unique(EBM_df$G_State))
# suppression des non-réponsesEBM_sel_df$D2_Nbansw<-as.numeric(EBM_sel_df$D2_Nbansw)EBM_sel_df <- EBM_sel_df[EBM_sel_df$D2_Nbansw>0,]
3.0.3.3 Assemblage des réponses dans un même character
Les réponses à la question posée sont stockées dans les variables l’identifiant de colonne commence par D2.
Dans la mesure où l’ensemble des réponses (“5 mots”) sont stockées dans cinq champs différents, on procède à leur assemblage dans un caractère unique qui vaudra comme un “texte” correspondant à chaque répondant. On pourrait tout aussi bien choisir de travailler sur une seule colonne (D2_anws1).
# assemblage des mots dans un character uniqueQuestD2_assembled_chr <-paste( EBM_sel_df$D2_answ1, EBM_sel_df$D2_answ2, EBM_sel_df$D2_answ3, EBM_sel_df$D2_answ4, EBM_sel_df$D2_answ5,sep =" ")# suppression des espaces vides avec la fonction gsubQuestD2_assembled_chr <-gsub(pattern="\\s+$","",QuestD2_assembled_chr)
3.0.4 Chargement des packages
Pour la suite du travail, nous avons de nouveau besoin des packages de quanteda ainsi qu’un ensemble de packages utiles pour l’analyse de données:
FactoMineR: est un package généraliste permettant d’effectuer des analyses factorielles et des classifications.
factoextra et explor sont des packages permettant la visualisation des sorties d’analyse factorielle (produites par FactoMineR).
See https://quanteda.io for tutorials and examples.
library(quanteda.textstats)library(quanteda.textplots)# Factominer pour l'analyse de données#install.packages("FactoMineR")library(FactoMineR)# Outils de visualisation des analyses factorielles#install.packages("factoextra")#install.packages("explor")library(factoextra)
Loading required package: ggplot2
Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBa
library(explor)
3.0.5 Définition du corpus d’étude et segmentation
Tokenisation, assignation des métadonnées et des id
# selection du texte à utiliserEBM_chr <- QuestD2_assembled_chr# segmentationEBM_tokens <-tokens(EBM_chr)# définition des métadonnéesdocvars(EBM_tokens) <- EBM_sel_df# définition des nomsdocnames(EBM_tokens) <- EBM_sel_df$Codeprint(EBM_tokens)
3.0.6 Construction d’un tableau lexical agrégé (TLA)
Dans le cadre de cette séance, chercherons l’existence de différences lexicales relativement à des variables caractérisant les étudiant·es, dans cet exemple le pays d’enquête.
Pour tester ces hypothèses, la plupart des méthodes proposées par la suite procèdent par l’analyse de tableaux dérivés du TLE (dfm): des tableaux lexicaux agrégés (TLA).
Les TLA sont des tableaux de contingence : ils représentent la sommes des fréquences de termes par sous-ensemble du corpus, définis à travers une modalité d’une variable qualitative nominale (ici G_country).
Dans quanteda, la construction du TLA s’effectue avec la fonction dfm_group() qui va procéder à l’agrégation des fréquences selon une variable d’agrégation identifiée par le paramètre group.
L’indicateur de sparcity (“rareté”) donne la proportion de cellules vides dans le tableau. Malgré l’agrégation, il reste relativement elevé.
# création d'un TLA selon la modalité de G_state (pays)EBM_country_dfm <-dfm_group(EBM_dfm,groups=G_State)print(EBM_country_dfm)
Document-feature matrix of: 4 documents, 2,323 features (66.28% sparse) and 2 docvars.
features
docs advanced country developed populated rich exploiter advance not corrupt
CMR 35 39 195 12 141 22 5 4 2
FRA 3 2 15 0 16 0 0 1 0
SWE 1 1 1 1 4 0 0 4 0
TUR 1 4 93 0 15 2 0 4 3
features
docs respect
CMR 5
FRA 4
SWE 0
TUR 7
[ reached max_nfeat ... 2,313 more features ]
3.0.7 Analyse des spécificités lexicales
Une première analyse consiste donc à procéder à un test statistique pour identifier les termes sur- et sous-représentés de manière significative par rapport à des distributions théoriques. Il existe différents tests statistiques pour mesurer les spécificités lexicales (cas du test de Lafon - 1980, dans TXM, test du chi2 - exemple dans Guérin-Pace, 1997).
Les termes dépassants le seuils statistiques fixé pour le rejet de l’hypothèse 0 (-3.841 et 3.841 pour le Chi2) sont dits spécifiques. On peut calculer des spécificités positives (surreprésentations) ou négatives (sous-représentations). Ceux situés en dessous de ce seuil sont dits banaux.
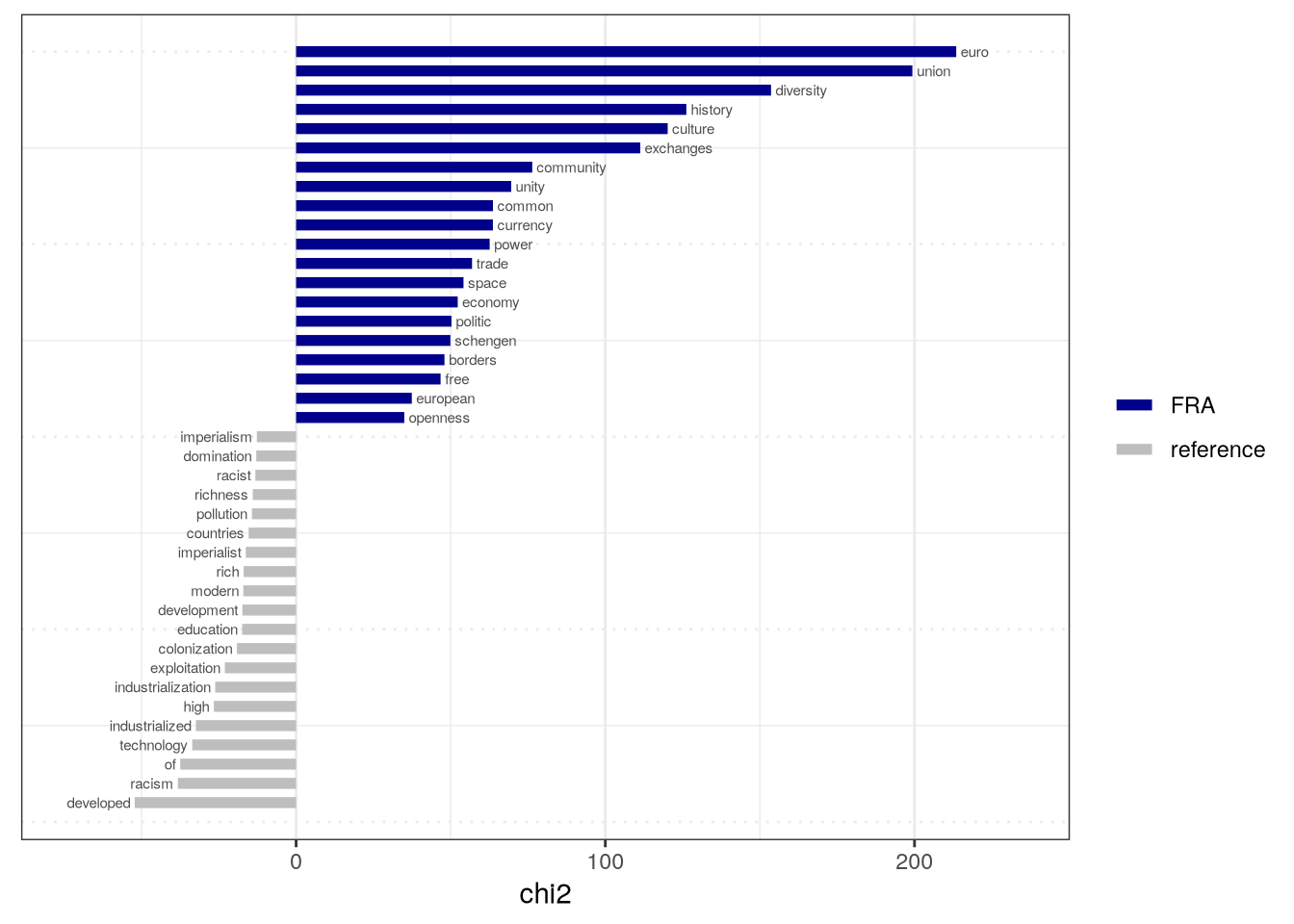
Quanteda utilise un test du Chi2 pour mesurer les écarts entre fréquences observées et fréquences estiméesvia la fonction textstat_keyness(). Cette fonction s’applique directement sur une dfm sur laquelle on a préalablement procédé à un regroupement (un TLA donc).
L’opération nécessite de définir une modalité cible (target), qui servira de référence pour le calcul du test. En effet, le test de spécificité cherche à établir des spécificités lexicales pour le sous-ensemble décrit par la modalité, par rapport au reste du corpus. En dehors des cas des analyses portant sur des variables binaires (deux modalités), le résultats ne permet donc pas d’identifier à laquelle des autres modalités il s’oppose.
Dans le cadre de cette analyse, on a procédé au préalable à un filtre pour ne retenir que les termes ayant une fréquence globale supérieur à 5 dans l’ensemble du corpus, avec la fonction dfm_trim vue plus haut.
# filtrage sur un nombre de fréquencesEBM_country_dfm_sel <-dfm_trim(EBM_country_dfm, min_termfreq =5)# test des spécificitéskeyness_df <-textstat_keyness(EBM_country_dfm, target ="FRA")as.data.frame(keyness_df)
Le résultat est stocké sous la forme d’un data.frame présentant, pour chaque forme, le résultat du test du Chi2, la p-value associée, sa fréquence dans le reste du corpus (appelée “n_reference”) et sa fréquence “locale” (dans le sous ensemble considéré, “n_target”).
Dans cette sortie, la fréquence globale n’apparait directement dans le tableau. Il faut donc procéder à une somme entre ces deux colonnes pour retrouver cette information.
# test des spécificitéskeyness_df$global <- keyness_df$n_target+keyness_df$n_referenceas.data.frame(keyness_df)
3.0.7.1 Visualisation graphique des spécificités
Quanteda propose une méthode de visualisation graphique des chi2 (diagramme à barres) calculés via l’outil textplot_keyness().
textplot_keyness(keyness_df, labelsize =2)
3.0.8 Exercice
A partir des données manipulées lors de la première partie de la journée, procédez à une analyse multifactorielle.
# on utilise la fonction de base saveRDSJO_tokens <-readRDS("data/corpusJOannote.RDS")# visualistion du tableau de donnéeshead(docvars(JO_tokens))
# pour rappel la liste des periodunique(docvars(JO_tokens)$period)
En tant qu’outil de statistique bivariée, l’analyse des spécificités a ses limites: elle ne permet pas d’analyser les spécificités de chaque texte l’un relativement à l’autre.
L’étape suivante consiste donc à procéder à une analyse factorielle des correspondances (AFC) sur le TLA, utilisé comme un tableau de contingence.
3.0.9 Analyse des correspondances appliquée au TLA
3.0.9.1 Principe général de l’AFC
L’analyse factorielle des correspondances (parfois simplement dite “analyse des correspondances”) nécessite elle aussi la transformation de données brutes, ici un corpus, en un tableau de contingence.
Ce tableau croise deux ensembles d’éléments, un ensemble I (individus ou observations) et un ensemble J (variables ou attributs). Au croisement d’une ligne et d’une colonne, on obtient le nombre d’occurrences de l’attribut j dans l’observation i, soit k (i, j). Il s’agit donc de ce que nous avons désigné comme un TLA.
Pour comparer la distribution des deux ensembles d’éléments, les profils de ligne et de colonnes sont calculés.
L’idée principale est de réduire la complexité du nuage et de trouver une façon de représenter la plus grande part de l’information dans un espace de dimension inférieure. Pour cela, le centre de gravité du nuage est calculé et la dispersion du nuage autour de son centre est mesurée (inertie).
Ensuite, les axes factoriels sont construits. Les points sont projetés sur ces axes, et leurs coordonnées sur ces axes sont appelées facteurs. Dans le plan défini par les deux premiers axes, nous pouvons avoir la meilleure projection du nuage (qui minimise la perte d’informations).
Un trait distinctif de l’analyse de correspondance est la symétrie parfaite des rôles assignés aux deux ensembles I et J. Cela permet la représentation simultanée des deux nuages sur les mêmes axes (donc sur le même plan factoriel).
L’objectif principal est de visualiser la distance entre les observations ou entre les attributs (variables): cette représentation permet de visualiser l’écart par rapport à une distribution aléatoire.
Elle est donc un outil d’exploration de données permettant d’observer conjointement les oppositions entre attributs (modalités de variables) et individus, donc leurs distances relatives.
Attention: Si l’analyse croisée des coordonnées des individus et des attributs est possible, il ce n’est pas le cas des cosinus et des contributions, puisque le calcul de ces éléments s’effectue sur les profils en ligne et en colonne (et non un croisement des deux).
Pour en savoir plus sur l’AFC voir Sanders, 1989, Lebart et Salem, 1994, Lebart et al., 2006.
3.0.9.2 Documentation dans R
De nombreux manuels et tutoriels existent sur l’application des méthodes d’analyse factorielles et leur visualisation dans R. On peut donc s’y référer pour comprendre la partie technique des applications et la méthodologie générale de l’AFC.
Husson, F. (dir.). (2018) R pour la statistique et la science des données. Presses Universitaires de Rennes
Husson, F. Lê S. & Pagès J. (2016) Analyse de données avec R, 2e édition revue et augmentée. Presses Universitaires.
Dans notre exemple, même principe que lors de la construction du TLA utilisé pour l’analyse des spécificités.
Avant de procéder on procède à la réduction de la taille de la matrice (dfm) puis une transformation de l’objet en objet matrix (changement de format) pour permettre son utilisation dans un outil généraliste d’analyse de données (hors de la suite quanteda).
# création d'un TLA selon la modalité de G_state (pays)EBM_country_dfm <-dfm_group(EBM_dfm,groups=G_State)# filtrage sur un nombre de fréquencesEBM_country_dfm_sel <-dfm_trim(EBM_country_dfm, min_termfreq =5)# transformation du tableau en matriceEBM_country_mat <-convert(EBM_country_dfm_sel,to="matrix")# transposition de la matrice pour faire apparaître les modalités en colonnesEBM_country_mat <-t(EBM_country_mat)
Dans l’exemple suivant, on applique la méthode d’analyse factorielle - fonction CA() proposée par le package FactoMineR. D’autres possibilités existent dans R, comme avec la fonction dudi.coa du package ade4.
Par défaut, seuls les 5 premiers axes sont conservés, ce qui est modifiable avec l’argument ncp. De plus, la fonction affiche par défaut un graphique des résultats avant de renvoyer les résultats de l’AFC Ce graphique peut être désactivé avec graph = FALSE.
# calcul de l'AFCafc_country <-CA(EBM_country_mat, graph =FALSE)# contenu de l'objet CAprint(afc_country)
**Results of the Correspondence Analysis (CA)**
The row variable has 357 categories; the column variable has 4 categories
The chi square of independence between the two variables is equal to 7851.969 (p-value = 0 ).
*The results are available in the following objects:
name description
1 "$eig" "eigenvalues"
2 "$col" "results for the columns"
3 "$col$coord" "coord. for the columns"
4 "$col$cos2" "cos2 for the columns"
5 "$col$contrib" "contributions of the columns"
6 "$row" "results for the rows"
7 "$row$coord" "coord. for the rows"
8 "$row$cos2" "cos2 for the rows"
9 "$row$contrib" "contributions of the rows"
10 "$call" "summary called parameters"
11 "$call$marge.col" "weights of the columns"
12 "$call$marge.row" "weights of the rows"
CA de FactoMineR produit un objet “CA”: un format de liste particulier, contenant les informations nécessaires pour l’interprétation des sorties.
# information sur les colonnesafc_country$col
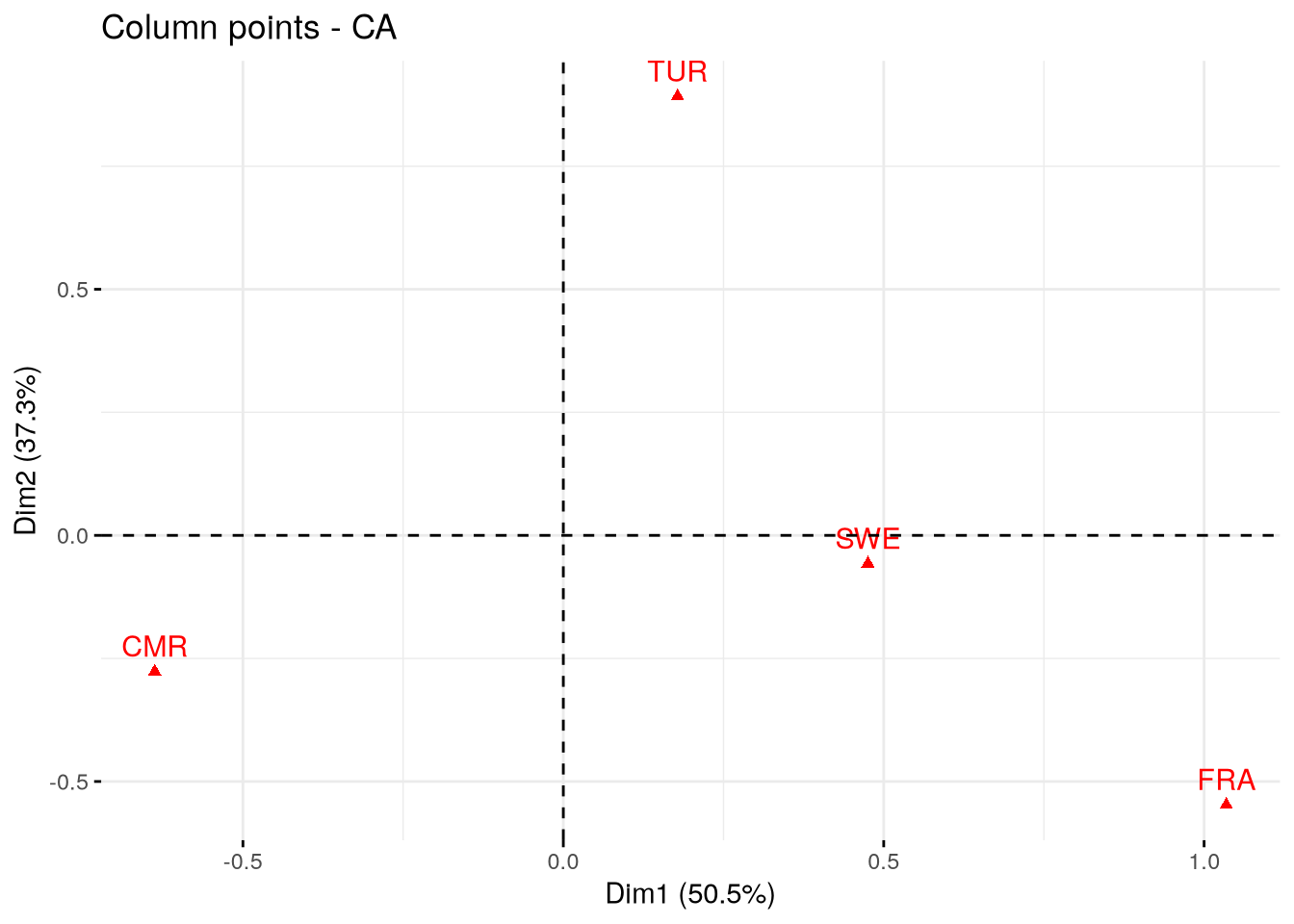
$coord
Dim 1 Dim 2 Dim 3
CMR -0.6376353 -0.27674762 -0.02198346
FRA 1.0347203 -0.54730884 -0.13353480
SWE 0.4753762 -0.05728668 1.77078676
TUR 0.1782719 0.89206799 -0.06260576
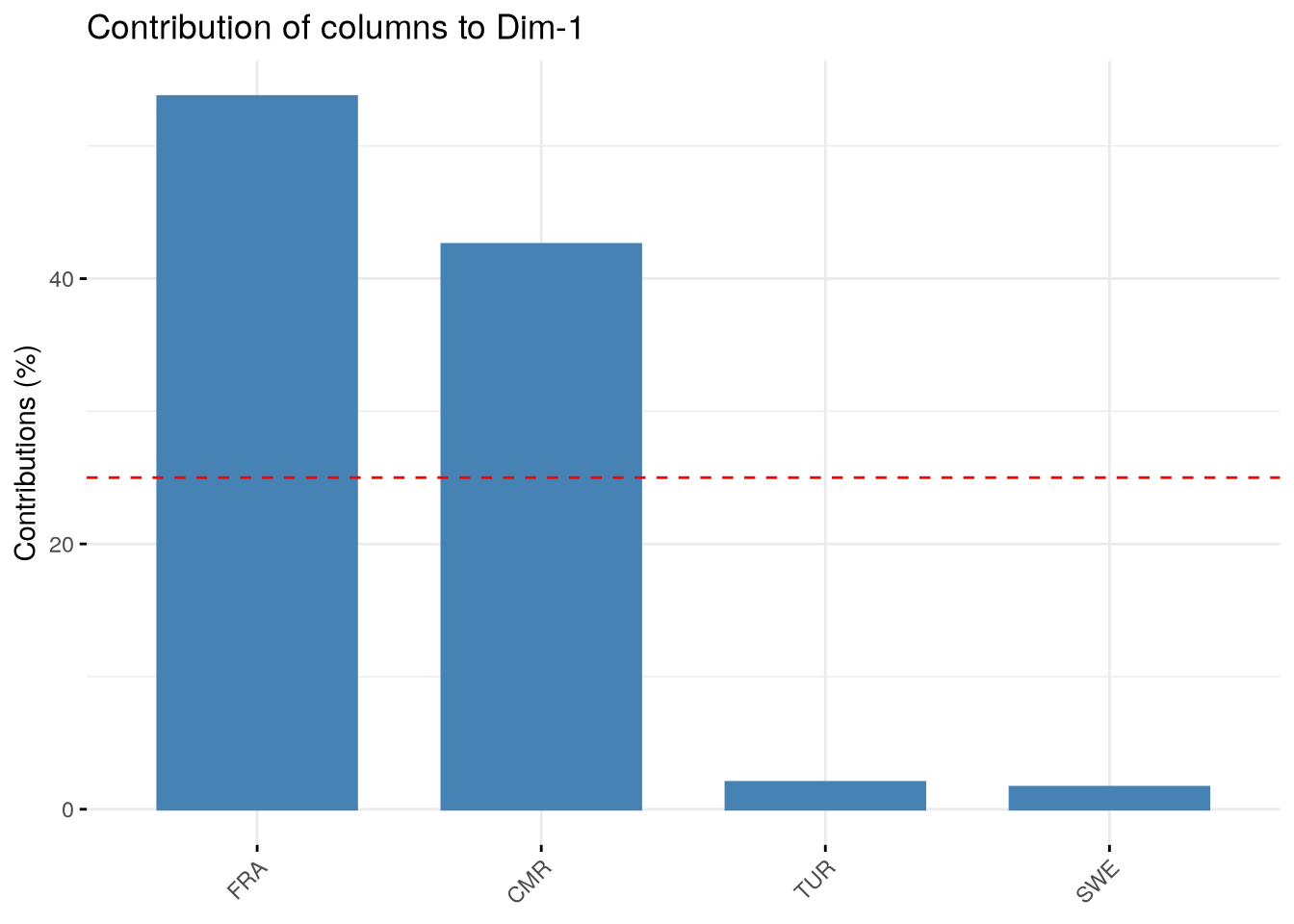
$contrib
Dim 1 Dim 2 Dim 3
CMR 42.583405 10.86740170 0.2090908
FRA 53.731974 20.36638733 3.6967740
SWE 1.658447 0.03262844 95.0618811
TUR 2.026174 68.73358253 1.0322541
$cos2
Dim 1 Dim 2 Dim 3
CMR 0.84064443 0.1583563495 0.0009992171
FRA 0.77134518 0.2158081175 0.0128467062
SWE 0.06715777 0.0009752785 0.9318669502
TUR 0.03822180 0.9570643710 0.0047138297
$inertia
[1] 0.2241245 0.3082090 0.1092614 0.2345454
# informations sur les lignesafc_country$row$coord[1:10]
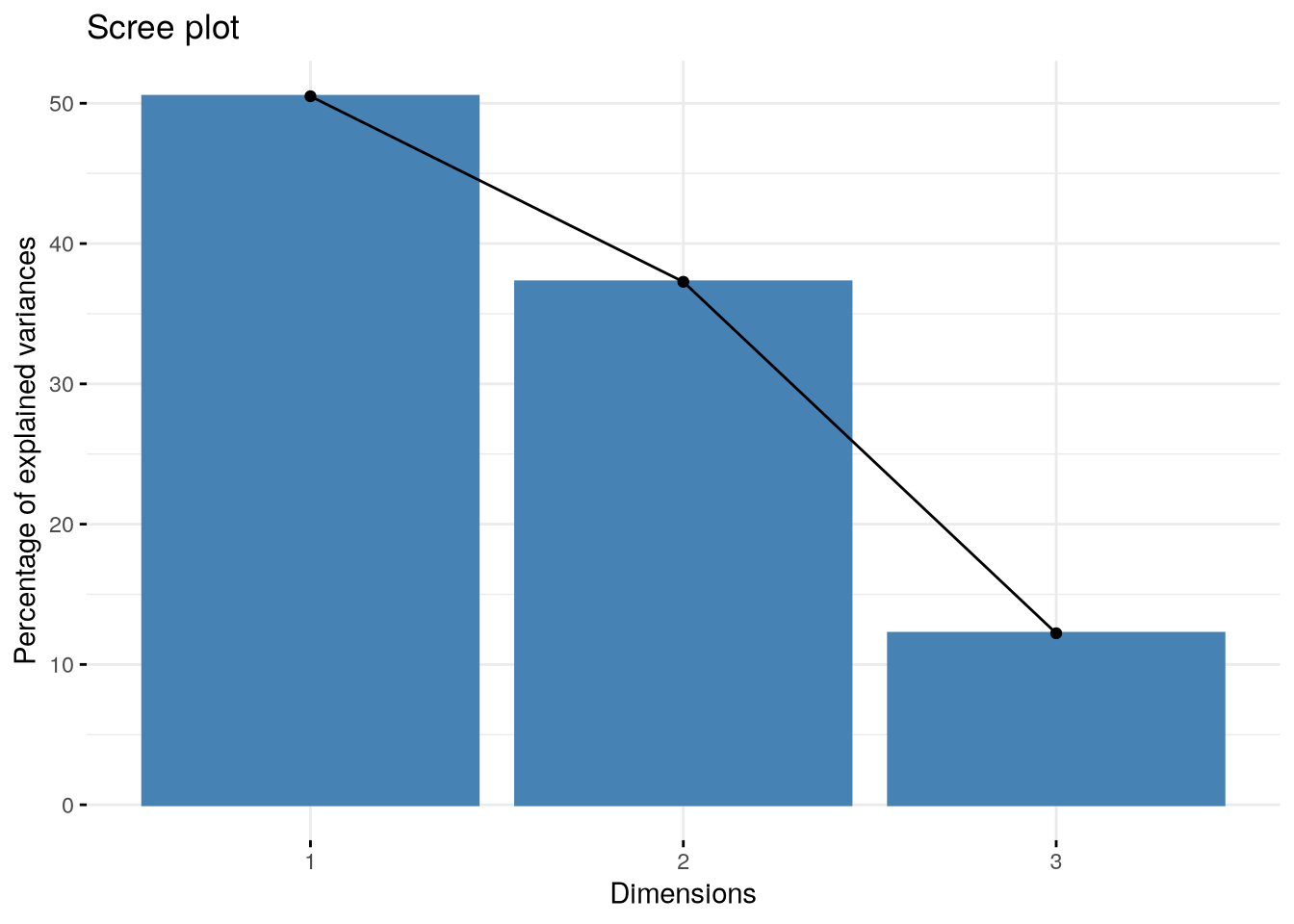
# informations sur les "valeurs propres" (eigen values - quantité de variance par axe)afc_country$eig
eigenvalue percentage of variance cumulative percentage of variance
dim 1 0.4424470 50.49957 50.49957
dim 2 0.3265871 37.27567 87.77523
dim 3 0.1071061 12.22477 100.00000
Elles peuvent notamment être utilisées pour produire les différentes visualisations graphiques (avec plot ou le package ggplot2 par exemple).
Des packages comme factoextra proposent des visualisations pré-définies de ce type d’objet.
3.0.10 Analyse des valeurs propres
Les valeurs propres et le pourcentage de variance expliquée donne une idée de la puissance explicative de chaque axe. Il s’agit de mesures de la quantité d’information résumée par l’axe (en valeur absolue et en valeur relative).
Le calcul des pourcentages de variance cumulée permet d’identifier le nombre d’axes à retenir pour l’analyse.
# valeurs propresfviz_screeplot(afc_country)
3.0.10.1 Contributions des axes
De même, il est possible d’analyser les contributions des modalités (colonnes) à chaque axe axes.
Cette information est complémentaire la puissance explicative de chacun d’entre eux.
3.0.10.2 Coordonnées des attributs / modalités de variables sur les axes
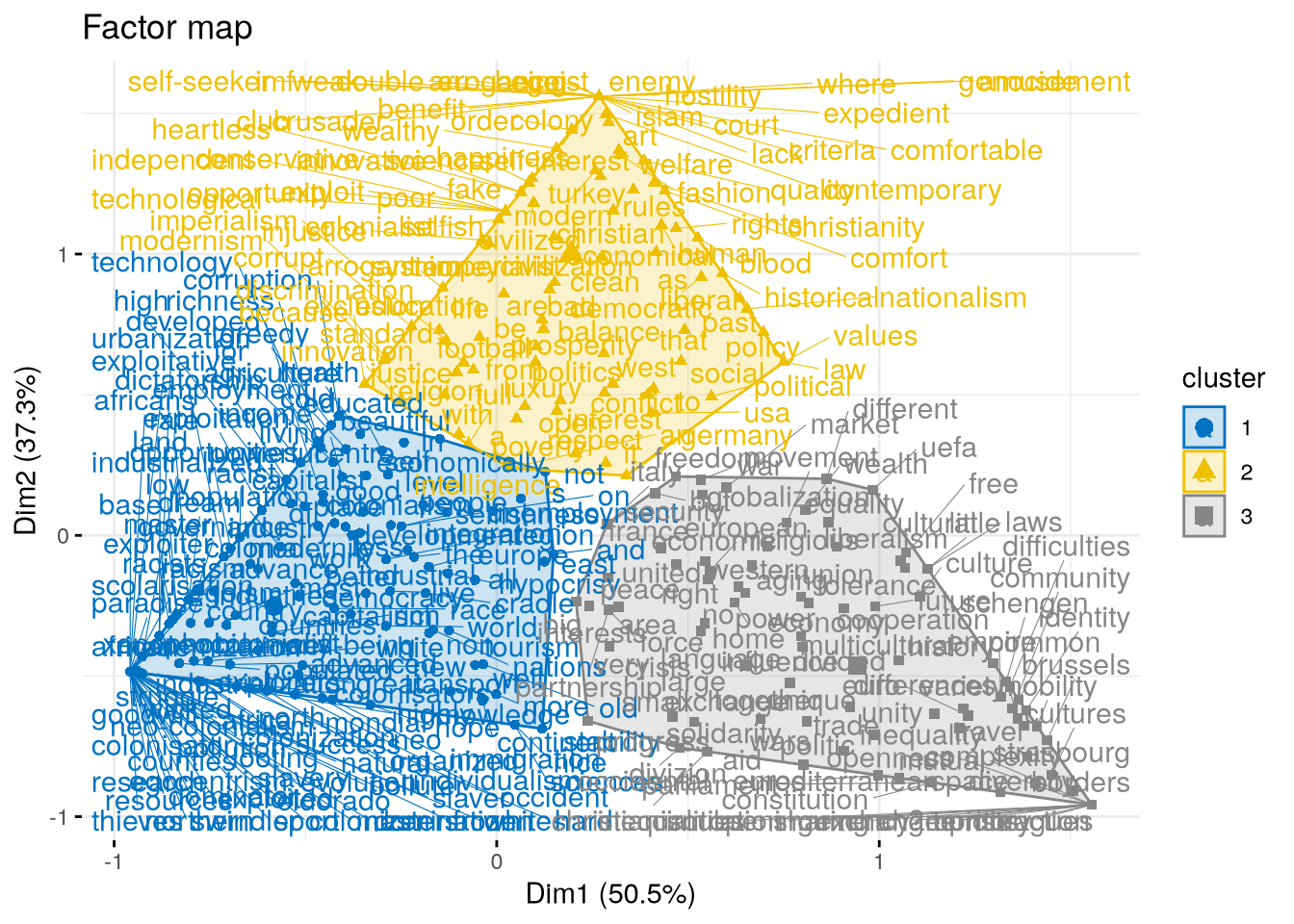
Enfin, conjointement à leur contribution, on analyse les coordonnées de chaque modalité de variable sur les axes. On procède généralement à la projection des coordonnées sur un graphique en deux dimensions croisant les coordoonées de deux axes (ici axe 1 et 2): un plan factoriel.
Plus une variable est éloignée du centre de gravité (0), plus le profil des individus qu’elle décrit se différencie du reste de l’ensemble.
Plus une variable est proche d’un axe, plus cela signifie que sa qualité de représentation sur cet axe est importante. Cette information doit croiser l’analyse des contributions (cos2 et pourcentage de variance expliquée élevés).
Enfin, notez que le signe des coordonnées est défini de manière arbitraire: il ne s’agit que d’une position relativement à une ordonnée. Le signe des coordonnées n’a aucune valeur en tant que tel.
Elle permet d’identifier des individus qui s’opposent sur un axe (Cameroun vs. France sur l’axe 1) ou au contraire qui se ressemblent (France et Sudède sur l’axe 1).
# Visualisation des colonnesfviz_ca_col(afc_country)
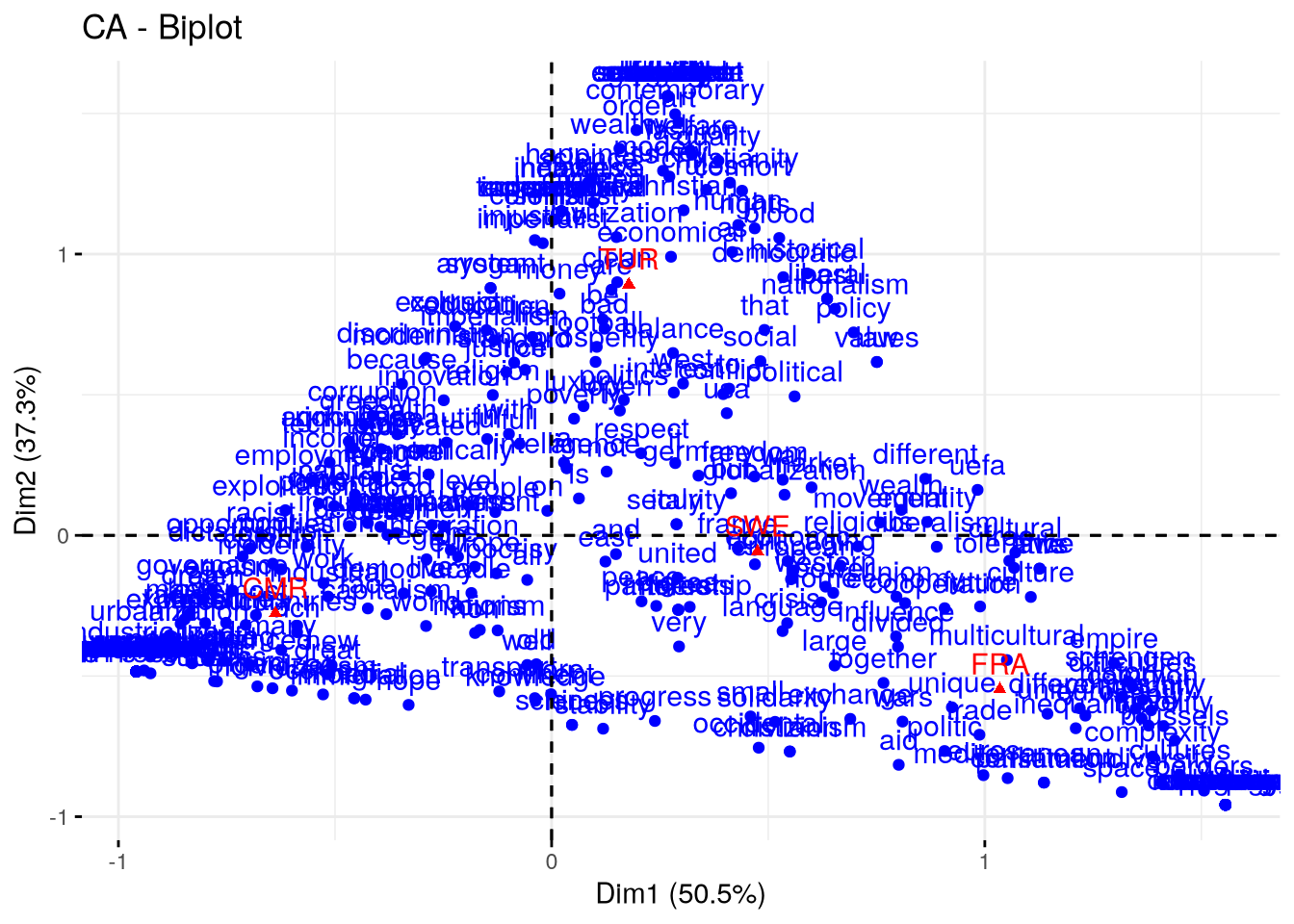
3.0.10.3 Représentation des individus (lignes) sur le plan factoriel
Le principe de l’analyse des invdividus est le même.
Le problème d’une telle représentation est qu’elle devient rapidement peu lisible.
# Visualisation des lignes avec factoextrafviz_ca(afc_country)
3.0.10.4 Visualisation intéractive avec explor
Le package explor permet d’explorer les sorties d’analyse factorielles de manière intéractive.
Note:Au-delà de la statistique textuelle, ce package s’applique à toute type d’analyse factorielle produite via les packages généralistes FactoMineR, ade4 et MASS).
#explor(afc_country)
3.0.10.5 Exercice
A partir des données manipulées lors de la première partie de la journée, procédez à une AFC sur le tableau de données.
3.0.10.6 Exports
En plus des exports graphiques, il est possible de procéder à l’export des tableaux ou variables.
Exemple, ici un tableau comprenant les informations relatives aux individus.
# création d'un tableau réunissant l'ensemble des informationstab_indiv <-cbind(row.names(afc_country$row$coord),as.data.frame(afc_country$row$coord),as.data.frame(afc_country$row$contrib),as.data.frame(afc_country$row$cos2))# réécriture des noms de colonnesnom_colonnes <-colnames(tab_indiv)nouveau_nom_colonnes <-c("mots",paste("coord",nom_colonnes[2:4],sep="_"),paste("contrib",nom_colonnes[5:7],sep="_"),paste("cos2",nom_colonnes[7:9],sep="_"))colnames(tab_indiv) <- nouveau_nom_colonnes# export write.csv(tab_indiv,"outputs/afc_country_indiv.csv",fileEncoding ="UTF-8")
3.0.11 Méthodes de classification: Classification Ascendante Hiérarchique
3.0.11.1 Principe général
Un des objectifs de la statistique textuelle peut-être de rechercher des similitudes entre les textes: est ce que certains texte ressemblent à d’autres du point de vue du lexique utilisé? Inversement, il est possible également de chercher des similitudes dans l’usage des mots (selon le contexte)?
Une grande diversité d’algorithmes de classification existent appliqués à l’analyse textuelle (classifications ascendantes, descendantes, méthodes de partition comme les kmeans).
Les deux premiers exemples montreront l’application d’une méthode de classification non-supervisée (on essaie de déterminer des classes uniquement à partir des données).
Elle est dite hiérarchique parce qu’elle construit des hiérarchie entre des niveaux d’agrégation possibles.
Dans le cas des classifications hiérarchiques, on parle de classification ascendante ou descendante pour caractériser le sens dans lequel l’algorithme a procédé pour construire la hiérarchie. Dans le cas des classifications ascendantes, l’agrégation procède au regroupement successif d’unités élémentaires (ici des mots) en fonction de leur ressemblance selon des critères de ressemblance. A l’inverse, une classification descendante hiérarchique (CDH) possède par division d’une classe initiale unique en sous ensembles.
La première étape considère les n individus (considérés comme autant de classes) caractrisés par p variables. La première étape consiste au regroupement des 2 individus les plus proches dans une première classe.
La deuxième étape dispose à ce niveau de (n-1) classes postérieures au regroupement des deux premiers individus. De la même manière, l’agorithme procède au regroupement des deux classes les plus semblables pour procéder au regroupement des deux classes les plus proches.
On procède ainsi de la même manière jusqu’à obtenir une classe unique regroupant l’ensemble des individus.
Cette procédure nécessite de définir un critère de ressemblance entre les individus (les plus courants: la distance euclidienne, chi2, manhattan, ces deux dernières sont utilisées pour les sorties d’AFC), la distance entre les classes (critères d’agrégation, ici méthode de ward).
Pour un point général sur les CAH, on peut se référer en géographie à Sanders 1989, en mathématique à Lebart et al, pour l’application de ces méthode à l’analyse de textes au Chapitre 4 de Lebart et Salem, 1994.
3.0.11.2 Implémentation dans R
Les liens suivants proposent deux fiches sur l’utilisation de la méthode HCPC dans R
Dans le cas de l’analyse de tableaux de contingences (comme nos TLA), une procédure classique consiste à procéder à une CAH sur les coordonnées de l’AFC.
La fonction HCPC() du package FactoMineR permet d’effectuer directement cette opération sur un objet de type CA (sortie d’AFC).
Le paramètre metric permet de caractériser la métrique de distance utilisée pour calculer les distances entre les classes (“manhattan”, ou “chi2”).
Le paramètre method permet d’indiquer le critère d’agrégation utilisé.
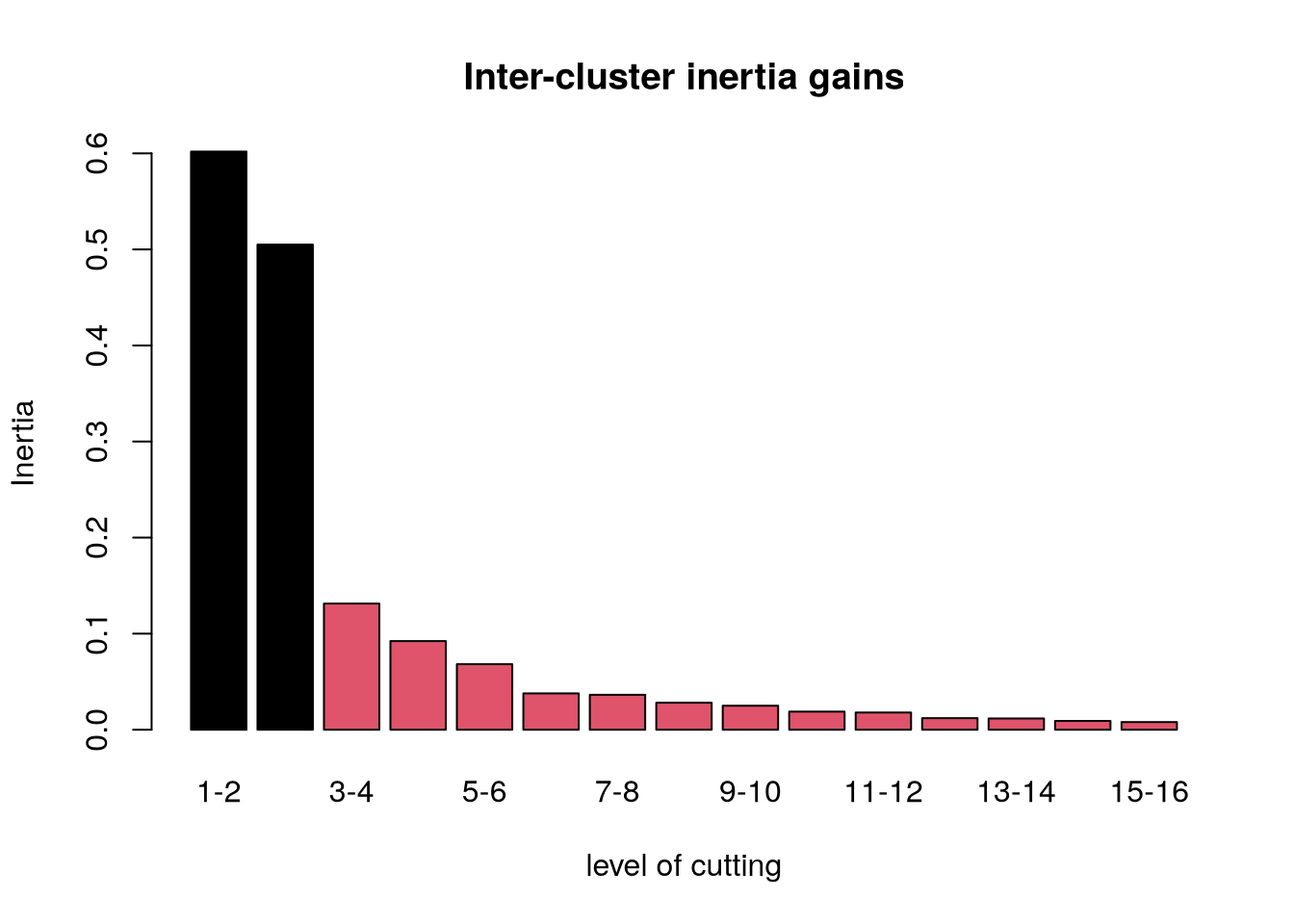
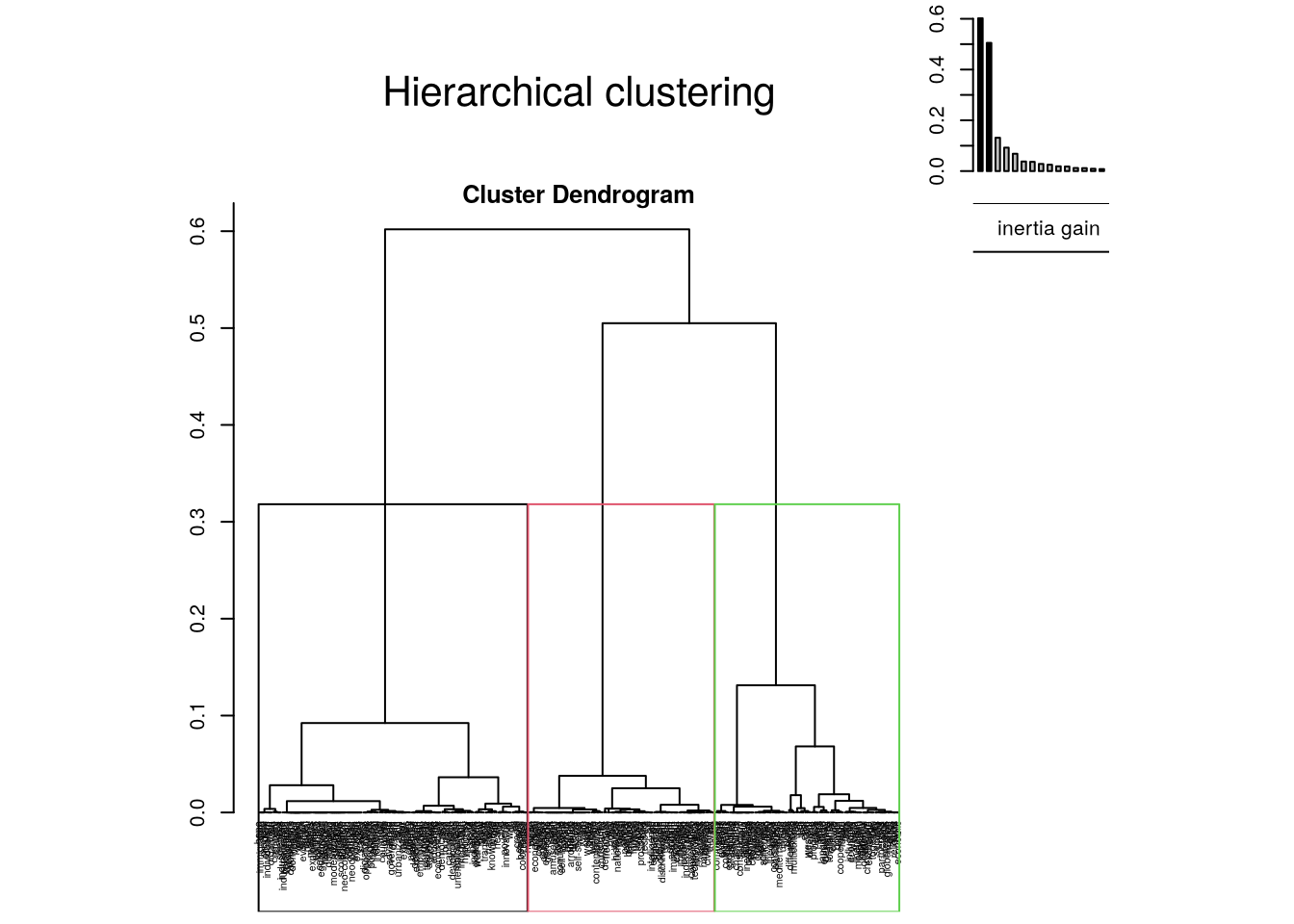
Pour étudier le résultat d’une CAH on passe généralement par l’analyse du dendrogramme (ou arbre), qui permet de visualiser la hiérarchie entre les classes par rapport à leur inertie. L’inertie, permet de visualiser la distance et donc en négatif la proximité entre chacune des classes formées.
# représentation de l'inertie sous la forme d'un diagramme à barreplot(res.hcpc, choice ="bar")
# représentation du dendrogrammeplot(res.hcpc, choice="tree", cex=0.5)
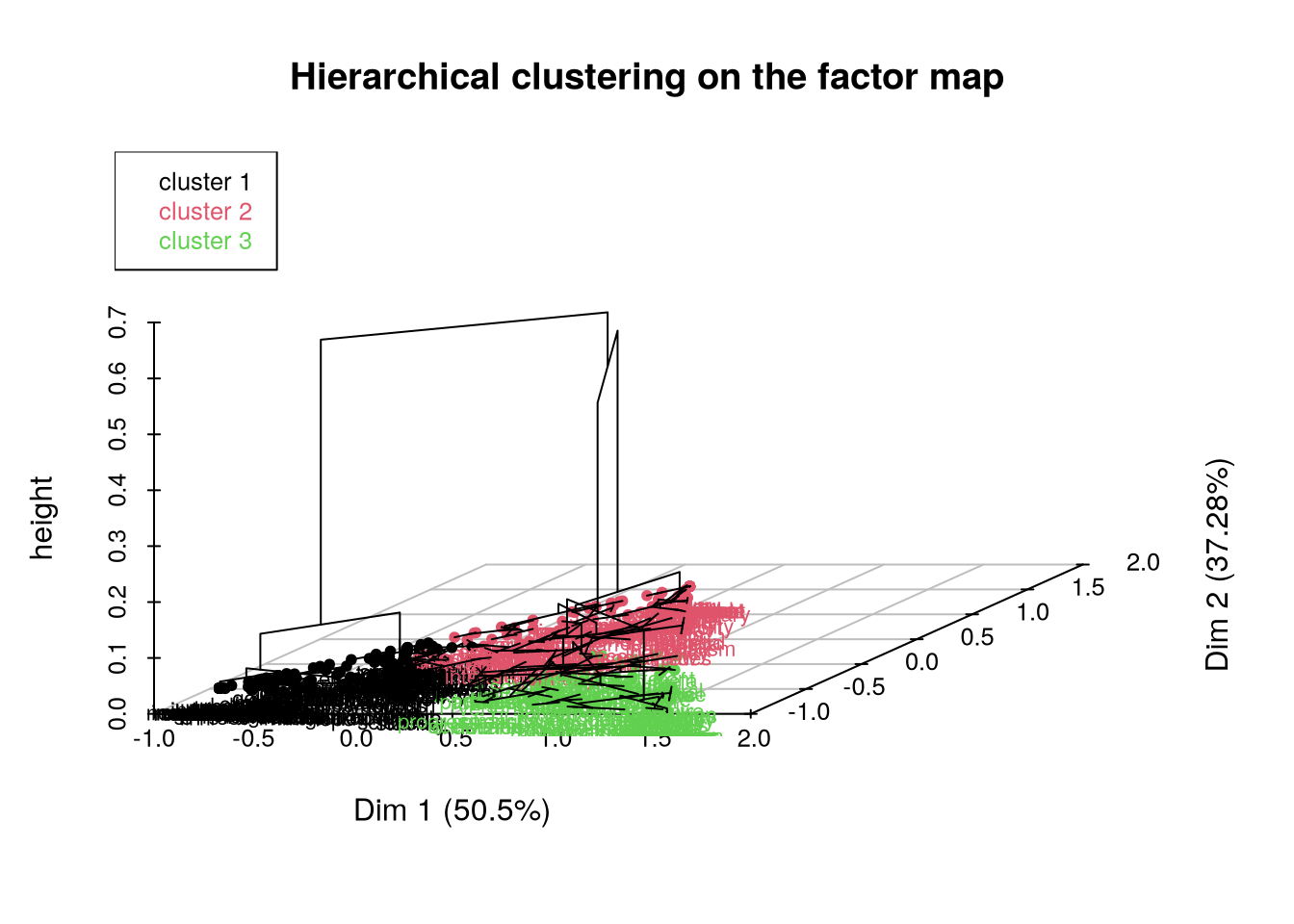
# dendrogramme en 3Dplot(res.hcpc, choice="3D.map", axes=c(1,2))
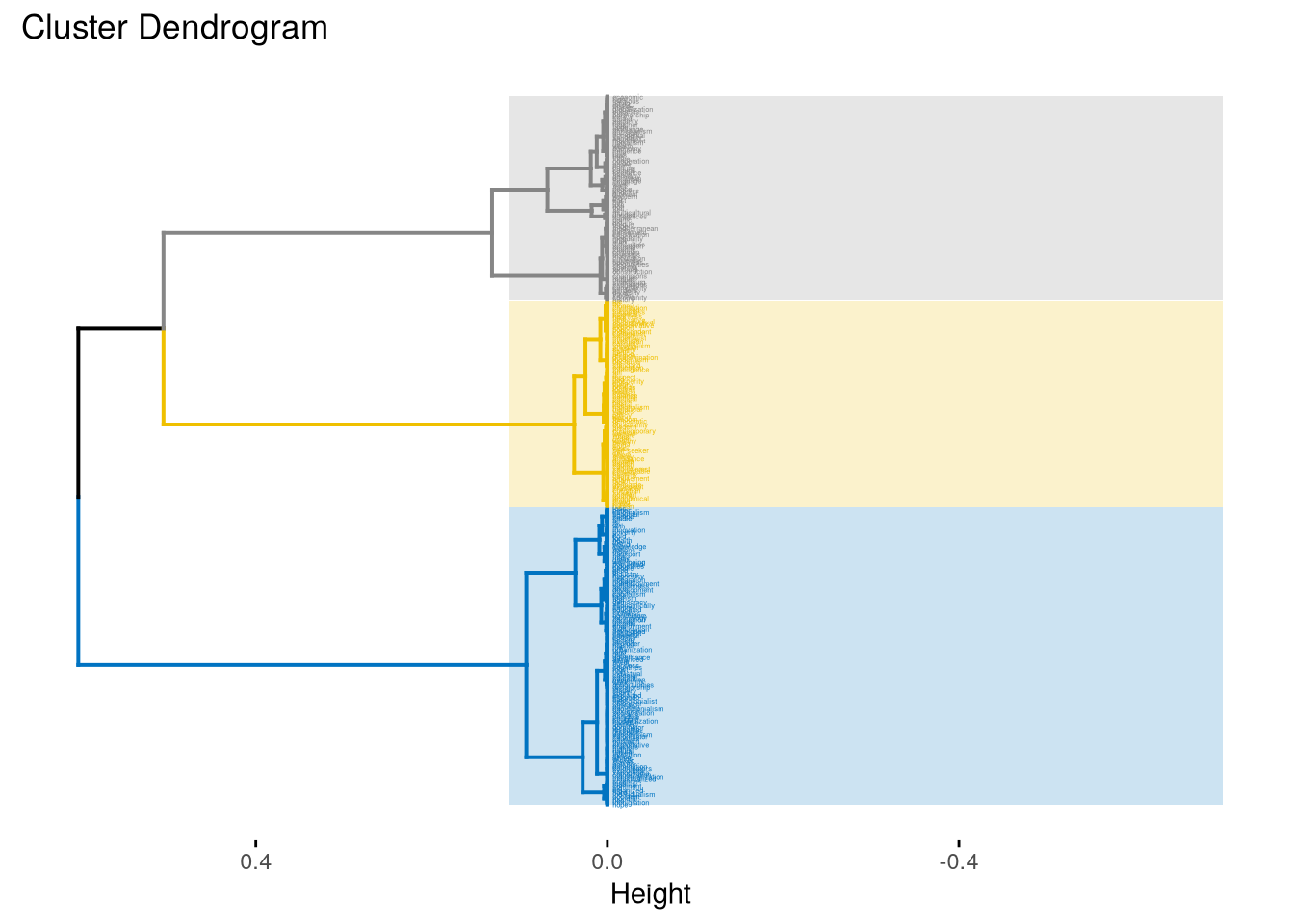
# représentations avec des couleursfviz_dend(res.hcpc, how_labels =TRUE, # Vizualise labelscex =0.2, # Label sizepalette ="jco", # Color palette see rect =TRUE, rect_fill =TRUE, # Add rectangle around groupsrect_border ="jco", # Rectangle colorlabels_track_height =0.2, # Augment the room for labelshoriz=TRUE )
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
ℹ The deprecated feature was likely used in the factoextra package.
Please report the issue at <https://github.com/kassambara/factoextra/issues>.
3.0.11.5 Analyse du contenu des classes
Certaines visualisations optent plutôt pour une représentation sur le plan factoriel d’origine.
# Représentation sur le plan factoriel.fviz_cluster(res.hcpc,repel =TRUE, # Avoid label overlappingshow.clust.cent =TRUE, # Show cluster centerspalette ="jco", # Color palette see ?ggpubr::ggparggtheme =theme_minimal(),main ="Factor map" )
3.0.12 Sorties de l’objet HCPC
Comme l’AFC, les classifications produites avec FactoMineR se présentent sous la forme de listes décrivant les individus et modalités de variables intégrées à l’analyse.
A partir des données manipulées lors de la première partie de la journée, procédez à une analyse multifactorielle. Rappel, l’objet créé pour réaliser l’analyse factorielle s’appelle afc_JO.
3.0.12.2 Bilan sur les analyses factorielles et les classifications
A partir de ce premier modèle d’analyse, une mutitude d’analyses complémentaires sont possibles en modifiant les différents paramètres
changer les unités lexicales (application à des segments répétés),
tester d’autres algorithmes de classification (comparaison avec un calcul de distance euclidienne, comparaison avec des méthodes de partitionnement: cas des kmeans).
Comme l’expliquent Lebart et Salem dans leur ouvrage, il est intéressant de mener conjointement plusieurs analyses pour tester leur robustesse, notamment dans le cas des méthodes de classification (cf. Lebart et Salem, Chapitre 4).
3.0.12.3 Segments répétés (ngrams)
Il est possible par exemple de procéder aux traitements en procédant cette fois-ci non plus aux analyses sur des mots mais sur des segments répétés (ngrams)
# cas des bigrammyngrams <-tokens_ngrams(JO_tokens, n =2, concatenator =" ")# création d'un ensenbme de ngrams de 1 à 4myngrams <-tokens_ngrams(JO_tokens, n =c(1:4), concatenator =" ")textstat_frequency(dfm(myngrams, tolower =FALSE))
3.0.13 Conclusion de la PARTIE 2
3.0.13.1 Derrière un ensemble limité d’exemples, une diversité de possibilités
Même si nous avons présenté une forme canonique d’analyse de données, une grande diversité d’adaptation est possible (changements de paramètres, recours à d’autres types d’analyses: autres méthodes de classification, d’analyse factorielle).
La très riche littérature consacrée à l’analyse des données depuis les années 1970 permet de s’orienter de manière autonome dans l’univers des méthodes possibles.
L’intérêt néanmoins de la méthode réside peut-être dans ces observations de L. Lebart cité dans Beaudouin, 2016 (nous soulignons).
“L’association de l’analyse des correspondances avec les méthodes de classification (en particulier la classification ascendante hiérarchique) permet d’approfondir la compréhension des données et facilite l’interprétation. « Ainsi une méthode unique dont le formulaire reste simple est parvenue à incorporer des idées et des problèmes nombreux apparus d’abord séparément, certains depuis plusieurs décennies. », écrit (Benzécri, 1982, p. 102). Comme l’explique Ludovic Lebart (communication personnelle), l’idée était de proposer « des panoplies bien étalonnées (comme le duo analyse des correspondances - classification) pour appréhender la complexité, sans chercher à créer systématiquement une nouvelle méthode pour chaque nouveau problème ».
Plutôt qu’une profusion de méthodes, difficiles à appréhender pour des non statisticiens, l’analyse des données offre un cadre unifié d’analyse avec le couple analyse des correspondances et classification. Celui-ci est clairement pensé pour les utilisateurs et les praticiens, en accordant une place importante à la présentation des résultats.”
3.0.13.2 R: diversité des outils, interfaçage et modularité
Cette diversité de méthodes est renforcée par la diversité des outils possibles dans R pour réaliser le travail. Nous avons par exemple privilégié une combinaison quanteda / FactoMinerR (avec des outils de visualisation factoextra et explor) mais d’autres solutions sont possibles : tidytext ou tm pour la manipulation de données, ade4 ou MASS pour l’analyse de données.
L’un des point fort de R est de pouvoir très facilement changer d’outil sans changer d’environnement de travail, de le connecter les fonctions spécialisées pour l’analyse textuelle à d’autres outils (visualisation, analyse statistique) voire créer des procédures sur mesure (création de vos propres sorties).
Le manque de visualisation intéractive qui donnait un avantage aux logiciels avec inerface graphique tend à être compensé par le développement de packages de visualisation intéractive (cf. explor).
Les possibilités de répétabilité des méthodes facilitent finalement les phases de pré-traitement qui tendent à devenir chronophage sur un logiciel sans langage de programmation.
3.0.13.3 Des solutions en dehors de R
Dans les cas où l’environnement R ne vous conviendrait pas, d’autres logiciels permettent d’effectuer les opérations présentées.
C’est notamment le cas de TXM développé par C. Heiden, qui dispose d’un coeur de fonction similaire à l’enchaînement proposé dans la Partie 2 (partition du corpus/construction d’un TLA, test de spécificité - test de Lafon, analyse des correspondances, CAH).