2PARTIE 1: Du texte au tableau, modéliser le corpus
2.0.1 Introduction
Le principe général de la statistique textuelle consiste à utiliser les méthodes de la statistique descriptive (analyse de distributions statistiques, tests statistiques, méthode de l’analyse de données) pour explorer le contenu d’un texte (statistique exploratoire).
Pour cela, on a recourt au formalisme de l’école française d’analyse de données (Benzecri, Lebart, Salem, Heiden, Guérin-Pace).
Le préalable à toute analyse est donc la modélisation du corpus à travers la construction d’un tableau statistique. La construction du tableau est postérieure à la construction du corpus et son annotation éventuelle.
Le terme de corpus désigne un assemblage de données divers (ici en occurence du texte) en vue de répondre à une problématique. Le corpus est donc la principale hypothèse d’un travail d’analyse textuelle.
La construction du corpus repose sur la connaissance du domaine d’étude par le/la chercheur·se. L’atelier proposé se situe donc a posteriori de la construction du corpus: dans les exemples proposés, on considère que la problématique, les hypothèses de travail, les sources et les données sont fixées. Pour des raisons de simplification, les bases de données et thèmes d’étude sont simplifiés pour permettre des manipulations.
2.0.2 Préparation des données: segmentation de texte et construction d’un TLE
Les deux premières étapes préalables à toute analyse consiste donc à :
passer d’un texte brut, stocké sous la forme de chaîne(s) de caractères dans un objet (dans R un character, un tableau/data frame, une liste chaînée/list) à un ensemble d’unités élémentaires (d’unités lexicales - formes et unités de contexte - textes). On appelle cette première étape la segmentation de texte ou tokenisation en anglais.
Ces unités élémentaires sont ensuite utilisées pour construire un tableau élémentaire de données. Ce tableau est appelé tableau lexical entier (TLE): il s’agit d’un tableau de dénombrement identifiant le nombre d’UL (colonnes du tableau) par UC (lignes).
Ces deux premières étapes précèdent les analyses des tableaux créés (calculs et visualisations éventuelles des tableaux). Dans la mesure où les résultats dépendront des différents choix effectués, ces étapes sont cruciales pour le paramétrage des analyses lexicales.
Cette première séance présente donc les outils permettant de réaliser la segmentation et la construction d’un TLE dans quanteda.
2.0.3 Modélisation des données dans Quanteda
Dans R, Quanteda procède à la création de différents objets qui vont correspondre aux produits des différentes étapes présentées plus haut. Chaque nouvel objet est donc le résultat de l’application d’une opération (implémentée dans une fonction) du package, éventuellement modifié par des fonctions auxilliaires.
Quanteda propose donc des fonctions spécialisées dans le traitement de données textuelles, produisant des objets eux aussi spécialisés pour stocker ce type de données.
2.0.3.1 Tokens, dfm et analyses
Même si chaque package d’analyse de données textuelles a ses caractéristiques, ils procèdent généralement en 3 étapes (cas par exemple de Tidytext )
Etapes de traitement de es données et création d’objets correspondants dans quanteda:
1- Segmentation et modélisation du corpus -> création d’un objet Tokens
2- construction d’un Tableau lexical (entier ou agrégé) -> création d’une dfm.
3- Analyse (statistique) -> analyse et création d’un objet (tableau ou graphique)
Les objets créés en étape 2 ou 3 peuvent être l’objet d’analyses via d’autres packages spécialisés pour l’analyse textuelle (Rainette) ou des packages généralistes (cas de packages d’analyse de données: ade4, Factominer, pour l’analyse ed données. C’est d’ailleurs ce que l’on présentera dans la deuxième partie de l’atelier.
2.0.4 Quanteda et ses extensions
Dans ses dernières versions, Quanteda est un ensemble de packages modulaires. L’outil est décomposé en plusieurs packages dont certains jouent le rôle d’extensions:
quanteda: Package coeur, gére les formats spécialisés de quanteda (corpus, Tokens, dfm) ainsi que des fonctions de gestion de données textuelles (gestion des unités lexicales: suppression, modification, détection de formes ; gestion des unités de contexte: suppression, ajout, découpage, assemblage des unités de contexte).
quanteda.textstats: est l’extension permettant d’effectuer des analyses statistiques sur les objets quanteda (construction de lexique, calcul d’indices de diversité lexicale, de spécificité, etc.)
quanteda.textplot: est l’extension permettant la réalisation de figures prédéfinies à partir des mêmes objets.
quanteda.textmodels: qui permet de traiter les sorties de modèle de langue (NLP).
2.0.5 Documentation
La documentation de quanteda, disponible en anglais, est très bien faite et régulièrement mise à jour par les dévelopeurs.
Elle propose un tutoriel ainsi qu’un glossaire des fonctions disponibles (reference). Dans ce glossaire chaque fonction est présentée avec un ou plusieurs exemples et des liens éventuels vers les publications présentant les outils avancés.
Elle est disponible en anglais sur le site du package, quanteda [https://tutorials.quanteda.io]
2.0.6 Installation des packages
Vérifions tout d’abord l’installation des différents packages.
Deux versions de quanteda sont disponibles,
la version 3.3.1 disponible sur le CRAN: il s’agit de la version stabilisée du package. Celle que nous allons utiliser dans le cadre de la formation.
la version 4.0.0 en développement: l’installation nécessite d’utiliser la fonction install_github pour l’installer. Voir la documentation.
# installation de la version 3.3.1# ---------------------------------# installation (si nécessaire) des packages#install.packages("quanteda")#install.packages("quanteda.textstats")#install.packages("quanteda.textplots")# chargement des packageslibrary(quanteda)
See https://quanteda.io for tutorials and examples.
library(quanteda.textstats)library(quanteda.textplots)# Installation de la version en déevloppement 4.0.0# ------------------------------------------------#remotes::install_github("quanteda/quanteda") # pour verifier la version installée on peut utilisersessionInfo()# -----------------------------------------------------------------sessionInfo()
2.0.7 Modélisation du corpus: définition des UL et des UC
2.0.7.1 Principe général
Le terme de modélisation est utilisé dans deux sens:
Au sens de formatage: formalisation informatique d’un outil permettant de représenter l’objet (ici des tableaux, des matrices et des listes).
Plus généralement, cette modélisation renvoie à la manière dont le corpus est pensé et structuré pour répondre à une ou plusieurs questions de recherche et hypothèses associées.
Ces deux niveaux de modélisation sont interdépendants.
Une problématique posant, par exemple une analyse par source, pour caractériser une différence de ligne éditoriale, par exemple (Libération vs. Le Figaro), devra permettre l’analyse croisée de sous-ensembles de sources composant le corpus. Ceci implique
d’avoir défini la source et les données utilisées ,
du point de vue des données d’avoir une variable permettant de construire des objets selon cette variable source (besoin d’une variable “source” décrivant les textes dans les métadonnées) .
Une étude s’intéressant à la variation d’un lexique dans le temps devra, lui, comporter une variable décrivant les textes selon une variable identifiant des périodes d’analyse.
La modélisation d’un corpus consiste donc à formater du texte (définition des UL et des UC) et des métadonnées (décrivant les UL et les UC).
Dans quanteda, deux types d’objets permettent de modéliser le texte avant de procéder à la construction du tableau de données préalable à l’analyse:
les objets corpus (non abordés ici), sont un format de stockage et de manipulation de données textuelles et de métadonnées (sous la forme de chaînes de caractères).
les objets Tokens, sont un format de stockage et de manipulation de textes pré-segmentés et de métadonnées.
Dans la mesure ou la création du premier est facultative, on se focalisera sur l’objet Tokens qui intervient lors de l’opération de segmentation (tokennisation): première étape de modélisation du texte sous la formes d’unités lexicales et d’unités de contexte.
2.0.7.2 Tokens et segmentation du texte
Un Tokens est un objet de type list spécifique à Quanteda composé:
De chaînes de caractères alpha-numériques (objet type character) représentant chaque texte associé à un identifiant.
Un ensemble de médatonnées (docvars) décrivrant le corpus et chacun des textes le composant.
La création d’un Tokens correspond à l’opération de segmentation d’un texte ou tokenisation en anglais. Il s’agit d’une « opération qui consiste à déterminer les unités minimales d’un texte » ( Lebart et Salem, 1994). Il s’agit donc de la décomposition d’une chaîne de caractères (classe d’objet character dans R) en unités élémentaires:
le plus souvent les unités lexicales (UL) sont des mots (mais il peut s’agir également de segments de textes),
les unités de contexte (UC) correspondent aux unités d’observation des UL. Selon le corpus, ces dernières peuvent être des phrases, des paragraphes, des pages, des articles de presse, des ouvrages, etc.. Par défaut, dans quanteda, elles correspondent aux différentes chaînes de caractères composant l’objet initial.
Les formes résultant de cette opération sont appelées occurences (ou tokens en anglais): “suite de caractères non délimiteurs bornée à ses extrémités par deux caractères délimiteurs de forme” ( ibid.).
Exemple de Tokennization
Voici deux exemples de textes chacun stockés dans un caractère. Choisissons en un pour procéder à sa ségmentation.
# Asimov, I., 1951, Foundation, New York, Gnome Press.asimov <-c( "Is name was Graal Dornick and he was just a country boy who had never seen Trantor before. That is, not real life. He had seen it many times on the hyper-video, and occasionally in temendous three-dimensional newscasts covering an Imperial Coronation of the opening of a Galactic Council. Even Though he had lived all his life on the world of Synnax, which circled a star at the edges of the Blue Drift, he was not cut off from civilization, you see. At that time, no place in the Galaxy was. \n There were nearly twenty-five million inhabited planets in the Galaxy then, and not one but owed allegiance to the Empire whose seat was on Trantor. It was the last half-century in which that could be said.")# S. Huntington, Le Choc des civilisations, 2000, Paris, Odile Jacob [traduction française]huntington_char <-c("A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir. Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques. Elles sont culturelles. Les peuples et les nations s’efforcent de répondre à la question fondamentale entre toutes pour les humains : qui sommes-nous ? Et ils y répondent de la façon la plus traditionnelle qui soit : en se référant à ce qui compte le plus pour eux. Ils se définissent en termes de lignage, de religion, de langue, d’histoire, de valeur, d’habitude et d’institutions. Ils s’identifient à des groupes culturels : tribus, ethnies, communautés religieuses, nations et, au niveau plus large, civilisations. Ils utilisent la politique pas seulement pour faire prévaloir leur intérêt, mais pour définir leur identité. On sait qui on est seulement si on sait qui on n’est pas. Et, bien souvent, si on sait contre qui on est.Les États-nations restent les principaux acteurs sur la scène internationale. Comme par le passé, leur comportement est déterminé par la quête de puissance et de la richesse. Mais il dépend aussi de préférences, de liens communautaire et de différences culturelles. Les principaux groupes d’État ne sont plus les trois blocs de la guere froide ; ce sont plutôt les sept ou huit civilisations majeures dans le monde . La richesse économique, la puissance économique et l’influence politique des sociétés non occidentales s’accroissent, en particulier en Extrême Orient. Plus leur pouvoir et leur confiance en elles augmentent, plus elles afforment leurs valeurs culturelles et rejettent celles que l’Occident leur a « imposées » ? « Le système international du XXIe siècle, notait Henry Kissinger, comportera au moins six grandes puissances – les Etats-Unis, l’Europe, la Chine, le Japon, la Russie et probablement l’Inde –n plus grand nombre de pays moyens et petits ».Les six grandes puissances selon Henri Kissinger appartiennent en fait à cinq civilisations très différentes. De plus, la situation stratégique, la démographie et/ou les ressources pétrolères de certains Etats musulmans importants rendent ces derniers très influents. Dans le monde nouveau qui est désormais le nôtre, la politique locale est ethnique et la politique globale est civilisatio+nnelle. La rivalité entre grandes puissances est remplacée par le choc des civilisations.Dans ce monde nouveau, les conflits les plus étendus, les plus importants et les plus dangereux n’auront pas lieu entre classes sociales, entre riches et pauvres, entre groupes définis selon des critères économiques, mais entre peuples appartenant à différentes entités culturelles. Les guerres tribales et les conflits ethniques feront rage à l’intérieur même de ces civilisations. Cependant, la violence entre les Etats et les groupes appartenant à différentes civilisations comportent un risque d’escalade si d’autres Etats ou groupes appartenant à ces civilisations se mettre à soutenir leurs « frères ».")# selectionmon_text_chr <- huntington_charprint(mon_text_chr)
[1] "A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir. Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques. Elles sont culturelles. Les peuples et les nations s’efforcent de répondre à la question fondamentale entre toutes pour les humains : qui sommes-nous ? Et ils y répondent de la façon la plus traditionnelle qui soit : en se référant à ce qui compte le plus pour eux. Ils se définissent en termes de lignage, de religion, de langue, d’histoire, de valeur, d’habitude et d’institutions. Ils s’identifient à des groupes culturels : tribus, ethnies, communautés religieuses, nations et, au niveau plus large, civilisations. Ils utilisent la politique pas seulement pour faire prévaloir leur intérêt, mais pour définir leur identité. On sait qui on est seulement si on sait qui on n’est pas. Et, bien souvent, si on sait contre qui on est.\nLes États-nations restent les principaux acteurs sur la scène internationale. Comme par le passé, leur comportement est déterminé par la quête de puissance et de la richesse. Mais il dépend aussi de préférences, de liens communautaire et de différences culturelles. Les principaux groupes d’État ne sont plus les trois blocs de la guere froide ; ce sont plutôt les sept ou huit civilisations majeures dans le monde . La richesse économique, la puissance économique et l’influence politique des sociétés non occidentales s’accroissent, en particulier en Extrême Orient. Plus leur pouvoir et leur confiance en elles augmentent, plus elles afforment leurs valeurs culturelles et rejettent celles que l’Occident leur a « imposées » ? « Le système international du XXIe siècle, notait Henry Kissinger, comportera au moins six grandes puissances – les Etats-Unis, l’Europe, la Chine, le Japon, la Russie et probablement l’Inde –n plus grand nombre de pays moyens et petits ».Les six grandes puissances selon Henri Kissinger appartiennent en fait à cinq civilisations très différentes. De plus, la situation stratégique, la démographie et/ou les ressources pétrolères de certains Etats musulmans importants rendent ces derniers très influents. Dans le monde nouveau qui est désormais le nôtre, la politique locale est ethnique et la politique globale est civilisatio+nnelle. La rivalité entre grandes puissances est remplacée par le choc des civilisations.\nDans ce monde nouveau, les conflits les plus étendus, les plus importants et les plus dangereux n’auront pas lieu entre classes sociales, entre riches et pauvres, entre groupes définis selon des critères économiques, mais entre peuples appartenant à différentes entités culturelles. Les guerres tribales et les conflits ethniques feront rage à l’intérieur même de ces civilisations. Cependant, la violence entre les Etats et les groupes appartenant à différentes civilisations comportent un risque d’escalade si d’autres Etats ou groupes appartenant à ces civilisations se mettre à soutenir leurs « frères »."
La tokennization s’effectue via la fonction tokens().
my_token <-tokens(mon_text_chr)print(my_token)
Tokens consisting of 1 document.
text1 :
[1] "A" "la" "fin" "des" "années"
[6] "quatre-vingt" "," "le" "bloc" "communiste"
[11] "s’est" "effondré"
[ ... and 527 more ]
La fonction de base de quanteda n’effectue, par défaut, aucune transformation sur l’objet initial, ce qui signifie que l’ensemble des formes introduites dans le texte se retrouvent telles quelles dans le Tokens créé.
Dans la mesure où l’on a introduit un objet unique contenant une seule chaîne de caractère la liste ne comporte qu’un seul objet par défaut dénommé “text1” (format des noms d’objets par défaut dans quanteda).
Des opérations de sélections sont possibles dès cette étape, en paramétrant la fonction. Il est par exemple possible, comme ci-dessous, de supprimer les signes de ponctuation (remove_punct), les caractères numériques (remove_numbers) ou encore les url (remove_url).
Tokens consisting of 1 document.
text1 :
[1] "A" "la" "fin" "des" "années"
[6] "quatre-vingt" "le" "bloc" "communiste" "s’est"
[11] "effondré" "et"
[ ... and 454 more ]
Pour créer un document contenant plusieurs textes il faut donc effectuer l’opération sur plusieurs chaînes de caractères assemblées dans un même objet.
Dans l’exemple suivant,
l’objet utilisé pour créer my_tokens2 est une une liste contenant deux chaînes de caractères.
dans le second cas, l’objet my_tokens3 est un tableau composé d’une colonne texte (“my_text”) et d’un identifiant (“my_text_name”). Dans ce cas-ci, on spécifie que la tokennization s’effectue sur la colonne contenant le texte (“my_text”).
# listemy_tokens2 <-c(text1="A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir.",text2="Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques.")tokens(my_tokens2)
Tokens consisting of 2 documents.
text1 :
[1] "A" "la" "fin" "des" "années"
[6] "quatre-vingt" "," "le" "bloc" "communiste"
[11] "s’est" "effondré"
[ ... and 16 more ]
text2 :
[1] "Dans" "le" "monde" "après" "la"
[6] "guerre" "froide" "," "les" "distinctions"
[11] "majeures" "entre"
[ ... and 11 more ]
print(my_tokens2)
text1
"A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir."
text2
"Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques."
# tableau## création d'un tableau titre / textemy_text <-c("A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir.","Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques.")my_text_name <-c("Huntington1","Huntington2")my_textual_df <-data.frame (my_text,my_text_name)# creation du tokensmy_tokens3 <-tokens(my_textual_df$my_text)print(my_tokens3)
Tokens consisting of 2 documents.
text1 :
[1] "A" "la" "fin" "des" "années"
[6] "quatre-vingt" "," "le" "bloc" "communiste"
[11] "s’est" "effondré"
[ ... and 16 more ]
text2 :
[1] "Dans" "le" "monde" "après" "la"
[6] "guerre" "froide" "," "les" "distinctions"
[11] "majeures" "entre"
[ ... and 11 more ]
Dans le troisième exemple (“my_tokens3”), un identifiant par défaut a été donné à mes textes dans le token. Pour redonner le nom original de mes textes, il suffit de le définir en assignant au tokens les identifiants, via la syntaxe suivante.
Comme la fonction de base names() on note que docnames() est à la fois une fonction de requête (appliquée à un corpus elle retourne la liste des identifiants) et d’assignation (réécriture de nouveaux identifiants à patir d’une liste)
# assignation des nouveaux nomsdocnames(my_tokens3)
[1] "text1" "text2"
# assignation des nouveaux nomsdocnames(my_tokens3) <- my_textual_df$my_text_name# quels sont les nouveaux noms des documentsdocnames(my_tokens3)
[1] "Huntington1" "Huntington2"
De la même manière, il est possible d’introduire des métadonnées décrivant l’objet Tokens.
Dans ce type d’objet, les médatonnées sont stockées dans un tableau de données (docvars) associé à la liste. On peut le requêter via la fonction docvars() qui retourne un tableau (vide dans cet exemple).
Le tableau de métadonnées docvars doit contenir le même nombre de lignes que le nombre de textes stockés dans l’objet.
Ci-dessous on assigne le tableau de données initial (après ajout d’une variable source) comme tableau de métadonnées.
# Quelles sont les métadonnée du corpusdocvars(my_tokens3)
# Ajout de métadonnéesmy_textual_df$source <-"Le Choc des civilisations"docvars(my_tokens3) <- my_textual_df# Ajout de métadonnéesdocvars(my_tokens3)
print(my_tokens3)
Tokens consisting of 2 documents and 3 docvars.
Huntington1 :
[1] "A" "la" "fin" "des" "années"
[6] "quatre-vingt" "," "le" "bloc" "communiste"
[11] "s’est" "effondré"
[ ... and 16 more ]
Huntington2 :
[1] "Dans" "le" "monde" "après" "la"
[6] "guerre" "froide" "," "les" "distinctions"
[11] "majeures" "entre"
[ ... and 11 more ]
Par défaut, la fonction tokens() propose une segmentation par mots. Mais il est également possible de procéder autrement.
# segmentation par caractèretokens(my_textual_df$my_text[1], what ="character")
Tokens consisting of 1 document.
text1 :
[1] "A" "l" "a" "f" "i" "n" "d" "e" "s" "a" "n" "n"
[ ... and 112 more ]
# segmentation par phrasetokens(mon_text_chr,what ="sentence")
Tokens consisting of 1 document.
text1 :
[1] "A la fin des années quatre-vingt, le bloc communiste s’est effondré, et le système international lié à la guerre froide n’a plus été qu’un souvenir."
[2] "Dans le monde après la guerre froide, les distinctions majeures entre les peuples ne sont pas idéologiques, politiques ou économiques."
[3] "Elles sont culturelles."
[4] "Les peuples et les nations s’efforcent de répondre à la question fondamentale entre toutes pour les humains : qui sommes-nous ?"
[5] "Et ils y répondent de la façon la plus traditionnelle qui soit : en se référant à ce qui compte le plus pour eux."
[6] "Ils se définissent en termes de lignage, de religion, de langue, d’histoire, de valeur, d’habitude et d’institutions."
[7] "Ils s’identifient à des groupes culturels : tribus, ethnies, communautés religieuses, nations et, au niveau plus large, civilisations."
[8] "Ils utilisent la politique pas seulement pour faire prévaloir leur intérêt, mais pour définir leur identité."
[9] "On sait qui on est seulement si on sait qui on n’est pas."
[10] "Et, bien souvent, si on sait contre qui on est."
[11] "Les États-nations restent les principaux acteurs sur la scène internationale."
[12] "Comme par le passé, leur comportement est déterminé par la quête de puissance et de la richesse."
[ ... and 12 more ]
2.0.8 Exercice:
Chargez le tableau data/JO2008-08-08_2021-08-07_annoted.csv sur les JO 2008. Il s’agit d’un tableau de données téléchargées sur le site Europresse.
Europresse est une base de données d’information, contenant des données de médias européens à laquelle sont abonnés la plupart des universités.
La sélection des données (articles et métadonnées) est effectuée via une requête par mots clefs. Dans ce cas on s’intéresse à la couverture médiatique des quatre derniers Jeux Olympiques d’été (Londres 2012, Beinjing 2008, Rio 2016, Tokyo2021). On a donc requêté les textes contenant les termes “Jeux Olympiques | JO” pour une période d’un mois à partir de la cérémonie d’ouverture.
Le tableau contient une colonne Titre, une colonne Date, une colonne Texte, une colonnes Source identifiant la source originelle, une colonne source2 indiquant la source secondaire (Europresse) et enfin une colonne period identifiant les JO.
Pour limiter les temps de calcul dans le cadre de cet exercice, le travail portera sur les Titres.
# chargement du tableautext_df<-read.csv("data/JO2008-08-08_2021-08-07_annoted.csv",fileEncoding ="UTF-8")# sélection du textesel_text <- text_df$Titre
Dans le bloc de code ci-dessous, procédez à la tokennization du corpus. Analysez la structure du corpus.
# Exercice 1
2.0.9 Construction du TLE
Dans quanteda une dfm (document-feature matrix), en français “matrice document-forme” est le tableau élémentaire créé à partir d’un Tokens. Une dfm n’est autre qu’un TLE:
chaque colonne correspond aux formes (unités lexicales) contenues dans le corpus.
chaque ligne correspond aux unités de contexte.
L’opération de segmentation intiale (création de l’objet Tokens) est une étape fondamentale dans la construction de ce tableau.
Création d’une dfm sur le corpus Europresse.
# Chargement du tableau et tokenisation (cf. points précédents)text_df<-read.csv("data/JO2008-08-08_2021-08-07_annoted.csv",fileEncoding ="UTF-8")sel_text <- text_df$Titremy_tokens <-tokens(sel_text, remove_punct =TRUE, remove_symbols =TRUE,remove_numbers =TRUE)docvars(my_tokens) <- text_df# création d'une dfmmy_dfm <-dfm(my_tokens)print(my_dfm)
Document-feature matrix of: 574 documents, 3,298 features (99.51% sparse) and 6 docvars.
features
docs accueillir les jo favorise la relance de l'économie une victoire
text1 1 1 1 1 1 1 1 1 1 1
text2 0 0 0 0 1 0 2 0 0 0
text3 0 0 1 0 1 0 1 0 0 0
text4 0 2 1 0 0 0 4 0 2 0
text5 0 1 0 0 0 0 1 0 0 0
text6 0 1 0 0 0 0 1 0 0 0
[ reached max_ndoc ... 568 more documents, reached max_nfeat ... 3,288 more features ]
2.0.10 Premières analyses exploratoires (lexique et concordance)
2.0.10.1 Le lexique
Lors de la construction du TLE, il est souvent nécessaire de procéder à des analyses exploratoires, comme par exemple en analysant le lexique du corpus.
De manière générale, le lexique peut se définir comme “l’ensemble virtuel des mots d’un langage” (Lebart et Salem, 1994).
Dans le cadre d’une analyse de statistique textuelle, le lexique désigne un tableau représentant le nombre de formes distinctes identifiées dans le texte par rapport à une fréquence (nombre d’occurences).
En pratique, le lexique est la somme en colonne du TLE (dfm).
2.0.10.2 Implémentation dans quanteda
Dans quanteda, calcul du lexique est effectué via la fonction textstat_frequency() qui crée un tableau de dénombrement sous la forme d’un data.frame.
# calcul du lexiquetextstat_frequency(my_dfm)
2.0.10.3 Wordclouds: visualisations graphiques de lexiques
Des visualisations graphiques des tableaux lexicaux sont disponibles via l’extension quanteda.textplots.
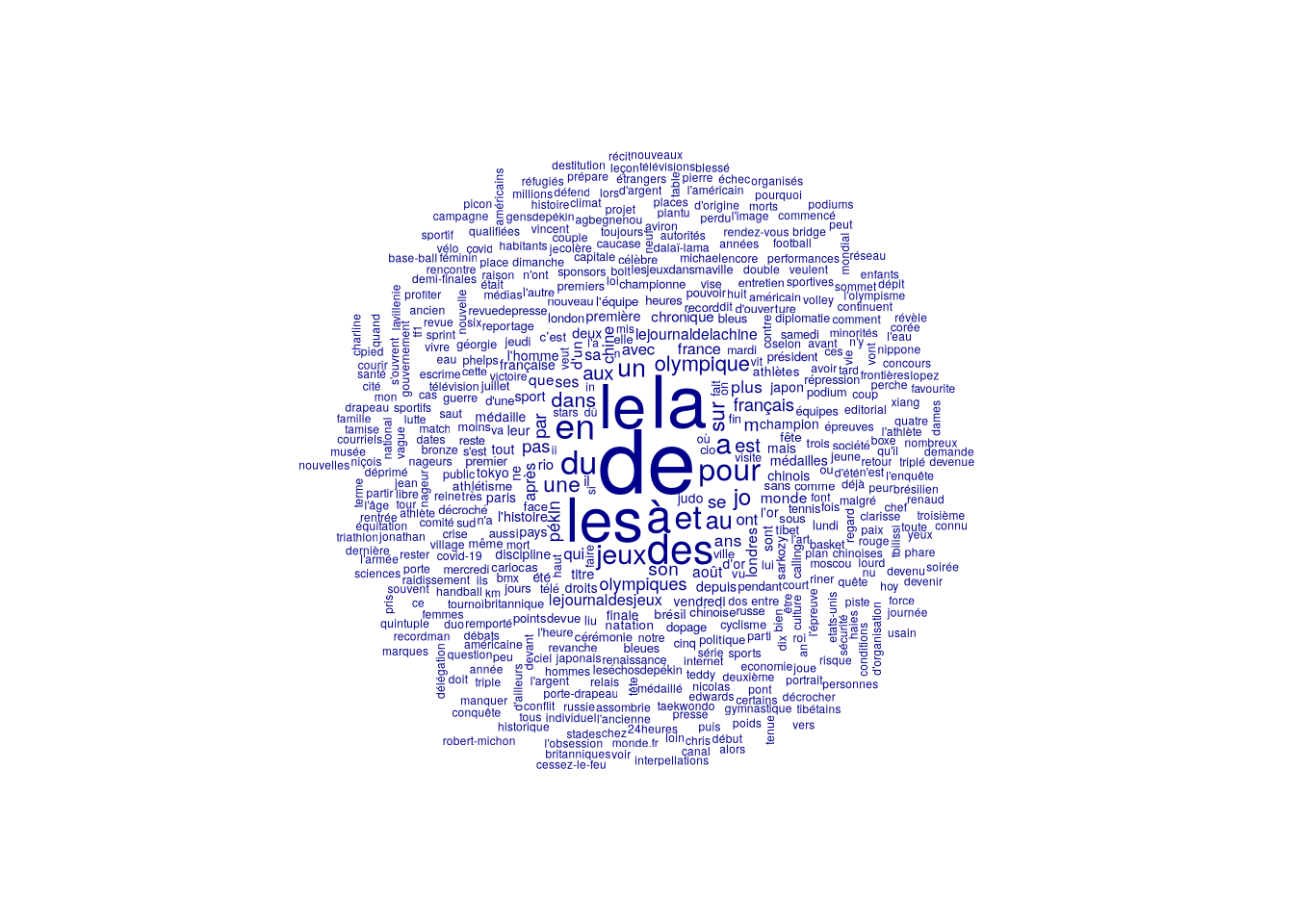
Dans le cas du lexique, quanteda propose la fonction textplot_wordcloud(), qui permet de générer des “nuages de mots” à partir des fréquences. Même si ces représentations posent problème en terme de sémiologie graphique, elles sont très utilisées à des fins de communication.
# fonction textplot wordcloud.textplot_wordcloud(my_dfm)
2.0.10.4 Loi de Zipf appliquée au lexique.
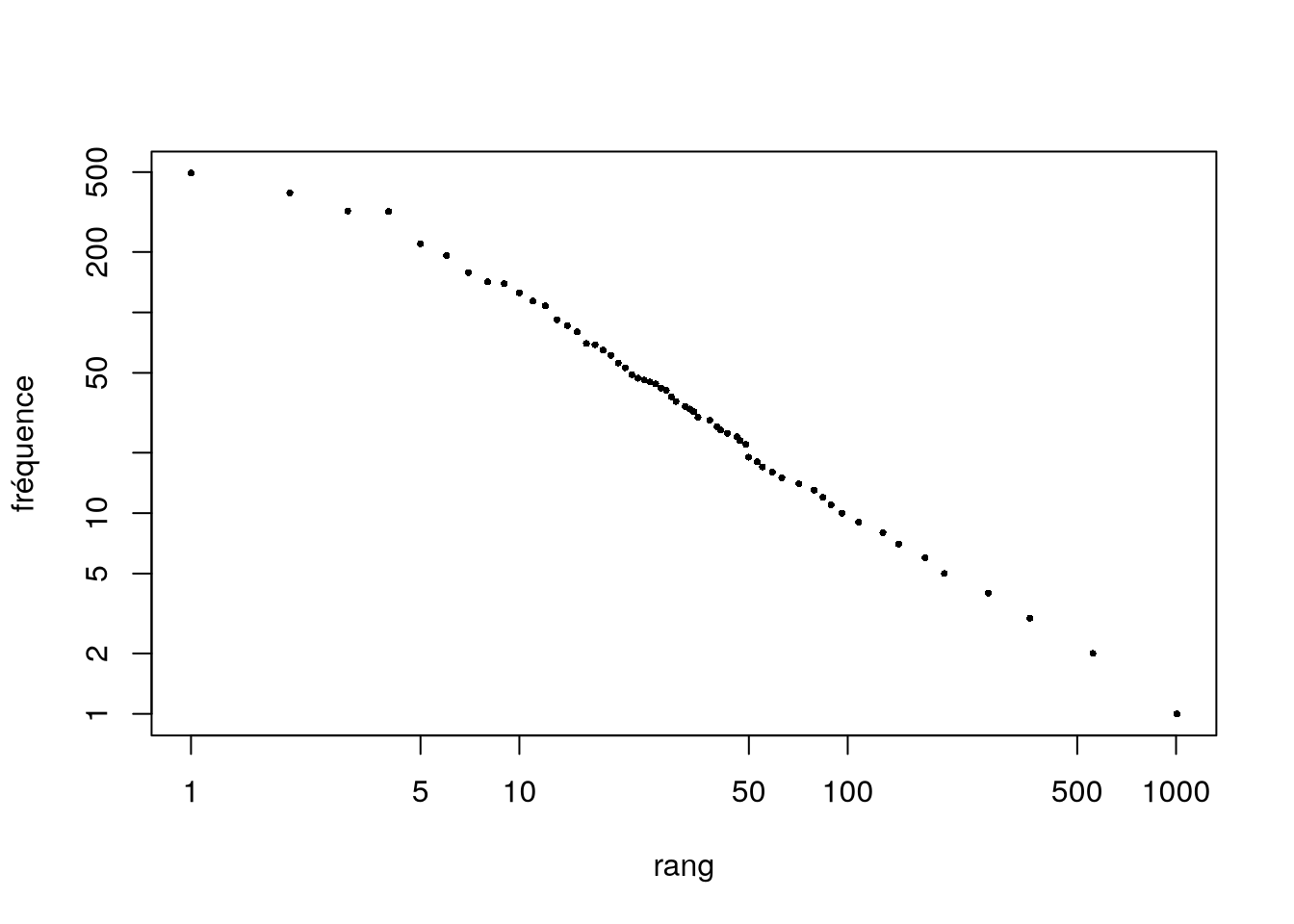
La distribution du lexique (rang / fréquences) n’est pas linéaire mais suit une fonction puissance.
# création du lexique dans un tableaulexique_df<-textstat_frequency(my_dfm)# courbe rang / fréquenceplot(lexique_df$rank, lexique_df$frequency, log ="yx", pch=16, cex=0.5,xlab ="rang",ylab="fréquence")
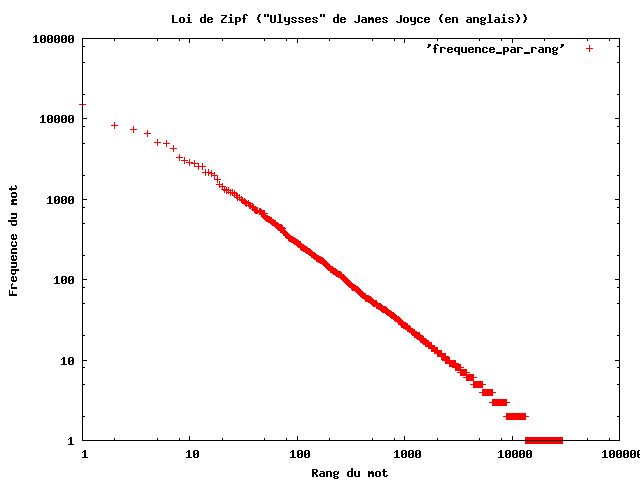
Cette distribution rang-taille correspond à la loi de Zipf observée dans l’analyse statistique de textes depuis les années 30 (Lebart et Salem, 1994).
Fig. 1: Exemple d’Ulysses de Joyce(Source: Lebart et Salem, 1994)
Fig. 2: Courbe forme / frequence (dite courbe de Zipf) sur Ulysses de Joyce
2.0.11 Les indices de diversité lexicale
En statistique textuelle, le calcul d’indices de diversité lexicale permettent de mesurer l’étendue du vocabulaire des textes relativement au nombre de fréquences totales.
Dans quanteda, plusieurs indicateurs de diversité lexicale sont disponibles pour procéder à leur calcul sur les textes via la fonction textstat_lexdiv(). L’indicateur proposé par défaut est le ratio entre le nombre de formes distinctes et le nombre d’occurences (dans quanteda TTR pour Type-Token Ratio).
Ce type d’analyse permet de vérifier l’homogénéité du corpus et d’identifier d’éventuels cas problématiques (exemple text98).
textstat_lexdiv(my_dfm)
2.0.11.1 Analyse des concordances
L’analyse des concordances est également précieuse: il s’agit de l’analyse d’une forme dans son contexte.
Dans quanteda, la fonction kwic() (keywords-in-context) permet d’analyser le contexte d’une forme définie par une requête (paramètre pattern). Le paramètre window définit la taille de la fenêtre d’observation en distance de mots.
Il est possible de procéder à des sélections avancées (usage d’expressions régulières ou au contraire identification littérale, voir “valuetype”).
# exemple 1kwic(sel_text,pattern="l'économie",window=3)
Warning: 'kwic.character()' is deprecated. Use 'tokens()' first.
# exemple 2: requête selon une racinekwic(sel_text,pattern="jap*",window=5)
Warning: 'kwic.character()' is deprecated. Use 'tokens()' first.
2.0.11.2 Bilan: lexique et concordances
L’analyse du lexique et des concordances constituent des étapes élémentaires préalables à toute analyse avancée pour caractériser le corpus et vérifier sa construction.
De fait, la construction d’un corpus pouvant généralement évoluer au fil de la recherche, ces outils sont utilisés dans la phase de construction de celui-ci (ajout/ suppression de textes, de sources).
Elles sont également utiles pour paramétrer le lexique afin de préparer des analyses statistiques plus avancées (du TLE).
2.0.12 Préparation du lexique
Selon l’analyse, il peut être intéressant de procéder à la transformations du lexique en intervenant directement sur les unités lexicales (ajout, suppression, remplacement, modification de formes).
Cette étape est importante, puisque ces unités élémentaires vont être la base, la matière première en quelque sorte, de toutes les analyses qui vont suivre.
Cette opération peut s’effectuer:
a posteriori de la tokenisation et avant la création de la dfm
ou a posteriori de la création d’une dfm.
2.0.12.1 Suppression de la casse
R est sensible à la casse. Les opérations effectuées sur les objets contenant des caractères alphanumériques feront donc la différences entre les formes commençant par une majuscule et les autres (“Etat”, “état”).
La suppression de la casse (passage en minuscule) peut-être un moyen de réduire la fréquence de certains termes. La fonction keep_acronyms permet de conserver des formes composées d’une succession de caractères en majuscule (donc, des sigles, potentiellement).
On peut également procéder à la sélection ou suppression de formes.
Par exemple, il est courant de procéder à la suppression des mots vides (stop words), qui peuvent encombrer les analyses lexicales avec une surreprésenation de faible intérêt.
Dans l’exemple suivant, on supprime ce type de mots à partir de listes pré-existantes via la fonction stopwords(), qui permet d’obtenir une chaîne de caractères de mots vides dans une langue choisie (ici en français). Le choix des mots vides est variable est lié aux roblématiques de recherche.
A ces éléments, on a ajouté un terme que l’on souhaite supprimer, le nom de deux rubriques rubrique “lejournaldesjeux” et “lejournaldelachine” qui apparaissent dans le lexique.
# application sur lemy_tokens_sel <-tokens_select(my_tokens_sel, pattern=c(stopwords("fr"),"lejournaldesjeux","lejournaldelachine"),selection="remove")# analyse du nouveau lexiquetextstat_frequency(dfm(my_tokens_sel))
2.0.12.3 remplacement de termes
La fonction token_replace() permet de remplacer des formes par d’autres.
Ici on a identifié que “JEUX” et “OLYMPIQUES” en majuscules avaient été identifiés comme des sigles. On va donc procéder à leur remplacement par “jeux” et “olympiques”.
Notez la syntaxe: le paramètre pattern permettant de détecter les termes correspont à un character dont les termes doivent correspondrent à un second character de termes de substitution. Il faut donc être vigilant·e lors de la construction de ces listes de termes pour que les termes et leur ordre d’apparition correspondent bien!
# sélection d'un textemy_tokens_sel <-tokens_replace(my_tokens_sel,pattern =c("JEUX", "OLYMPIQUES"),replacement =c("jeux","olympiques"))
2.0.12.4 Assemblages de termes (compounds)
Enfin, il peut également être pertinent de procéder à des rassemblements sémantiques, comme la construction de formes correspondant à des syntagmes: “états” “unis” deviendra “états_unis”
La fonction tokens_split() permet de découper des formes selon un séparateur défini. Cette fonction est très utile en français, par exemple, pour supprimer les apostrophes et les tirés.
# suppression des traits d'unionmy_tokens_sel <-tokens_split(my_tokens_sel, separator="-")# suppression des apostrophesmy_tokens_sel <-tokens_split(my_tokens_sel, separator="'")
L’ordre d’enchaînement des manipulations est donc crucial: les deux dernières opérations vont par exemple nécessiter de supprimer certaines formes isolées.
Ce point va de pair avec la dimension intrinsèquement exploratoire de la statistique textuelle: l’exploration du lexique accompagne la transformation du corpus et peut nécessiter des allers retours vers les hypothèses de travail.
En tant que langage de programmation facilité la répétibilité de la chaîne de traitement: il suffit de réexécuter le script après modification. La transformation de la chaîne de traitement s’interromp lorsque le résultat est jugé satisfaisant.
Ce travail de construction du corpus et du lexique est donc semi-automatique: plusieurs étapes nécessitent une intervention de l’utilisateur·ice.
2.0.13 Définition de sous-corpus
Pour travailler sur des sous corpus, c’est à dire un sous-ensemble de textes sélectionné selon un critère (par exemple une caractéristique des métadonnées), la fonction tokens_subset() permet d’effectuer l’opération à partir des informations stockées dans le tableau docvars.
Imaginons que l’on souhaite travailler uniquement sur le lexique des JO de Londres, on aura donc:
# construction d'un sous-corpus exclusivement sur les JO de LondresLondres2012_tkn <-tokens_subset(my_tokens_sel,period =="Londres2012")# calcul du lexique sur la dfmtextstat_frequency(dfm(Londres2012_tkn))
L’un des gros avantage de quanteda est qu’il reprend par défaut la structure des données et les métadonnées du Tokens lors de la création de la dfm.
Il est donc possible de procéder à ce type d’opération a posteriori de la construction d’une dfm! Il est ainsi possible de modifier le corpus et le lexique à plusieurs étapes de la chaîne de traitement, ce qui peut-être utile lorsque l’on envisage des analyses de type différents.
# d'une dfm sur l'ensemble du corpusmy_dfm <-dfm(my_tokens_sel)head(docvars(my_dfm))
# calcul du lexique sur la dfmTokoyo2021_dfm <-dfm_subset(my_dfm,period =="Tokyo2021" )textstat_frequency(Tokoyo2021_dfm)
2.0.14 Recherche de termes par dictionnaires
Le lexique présente l’ensemble des formes distinctes présentes dans un corpus. Cependant, il est parfois intéressant de raisonner sur un nombre restreint d’éléments: une liste de termes (dictionnaire, index).
2.0.14.1 Construction d’un dictionnaire
Quanteda comporte des fonctions prédéfinies pour des dictionnaires contenus dans des formats spécifiques, les objets de type dictionnary dans quanteda.
Il s’agit d’une liste associant à un identifiant un ensemble de formes stockées dans des objets de type character. Il est ainsi possible de détecter des objets associés à différentes formes (flexions d’une même racine, synonymie).
Ci-dessous nous créons un dictionnaire identifiant le Royaume-Uni (identifiable via un code iso “GB”) à travers une liste de termes considérés comme associés.
# création d'un dictionnaire à partir d'une listedict_GB <-dictionary(list(GB =c("royaume-uni", "grande-bretagne", "anglais*","britannique*", "londres")))print(dict_GB)
# Option qui créee un token qui conserve toutes les formesGB_detect2 <-tokens_lookup(my_tokens_sel, dictionary = dict_GB,exclusive =FALSE)print(GB_detect2)
2.0.14.3 Un premier pas vers la détection d’entités spatiales
Des dictionnaires pré-implémentés existent dans certains packages, comme le package newsmap (Watanabe, 2017), qui propose des dictionnaires dans différentes langues en vue de l’annotation (étiquetage, tagging) de corpus. Il est développé par des collègues de sciences politiques et des media studies pour analyser la représentation des Etats dans la presse.
Dans l’exemple suivant, on utilise le dictionnaire newsmap, pour détecter les Etats du Monde présents dans le corpus sur les Jeux Olympiques.
Comme l’objet produit est un Tokens, on crée directement une dfm à partir de cet objet sur le sous-corpus traitant des JO de Beinjing, puis le lexique associé.
#install.packages("newsmap")library(newsmap)# detection à partir du dictionnaire newsmaptoks_countries <-tokens_lookup(my_tokens, dictionary = data_dictionary_newsmap_fr, levels =3)# creation d'une dfm (tableau lexical) sur le textedfm_countries <-dfm(toks_countries, tolower =FALSE)dfm_subset(dfm_countries,period="Beinjing2008")
Warning: period argument is not used.
Document-feature matrix of: 574 documents, 241 features (99.74% sparse) and 6 docvars.
features
docs BI DJ ER ET KE KM MG MU MW MZ
text1 0 0 0 0 0 0 0 0 0 0
text2 0 0 0 0 0 0 0 0 0 0
text3 0 0 0 0 0 0 0 0 0 0
text4 0 0 0 0 0 0 0 0 0 0
text5 0 0 0 0 0 0 0 0 0 0
text6 0 0 0 0 0 0 0 0 0 0
[ reached max_ndoc ... 568 more documents, reached max_nfeat ... 231 more features ]
# creation d'un tableau de fréquences avec le nombre de pays df_freq <-textstat_frequency(dfm_countries)df_freq
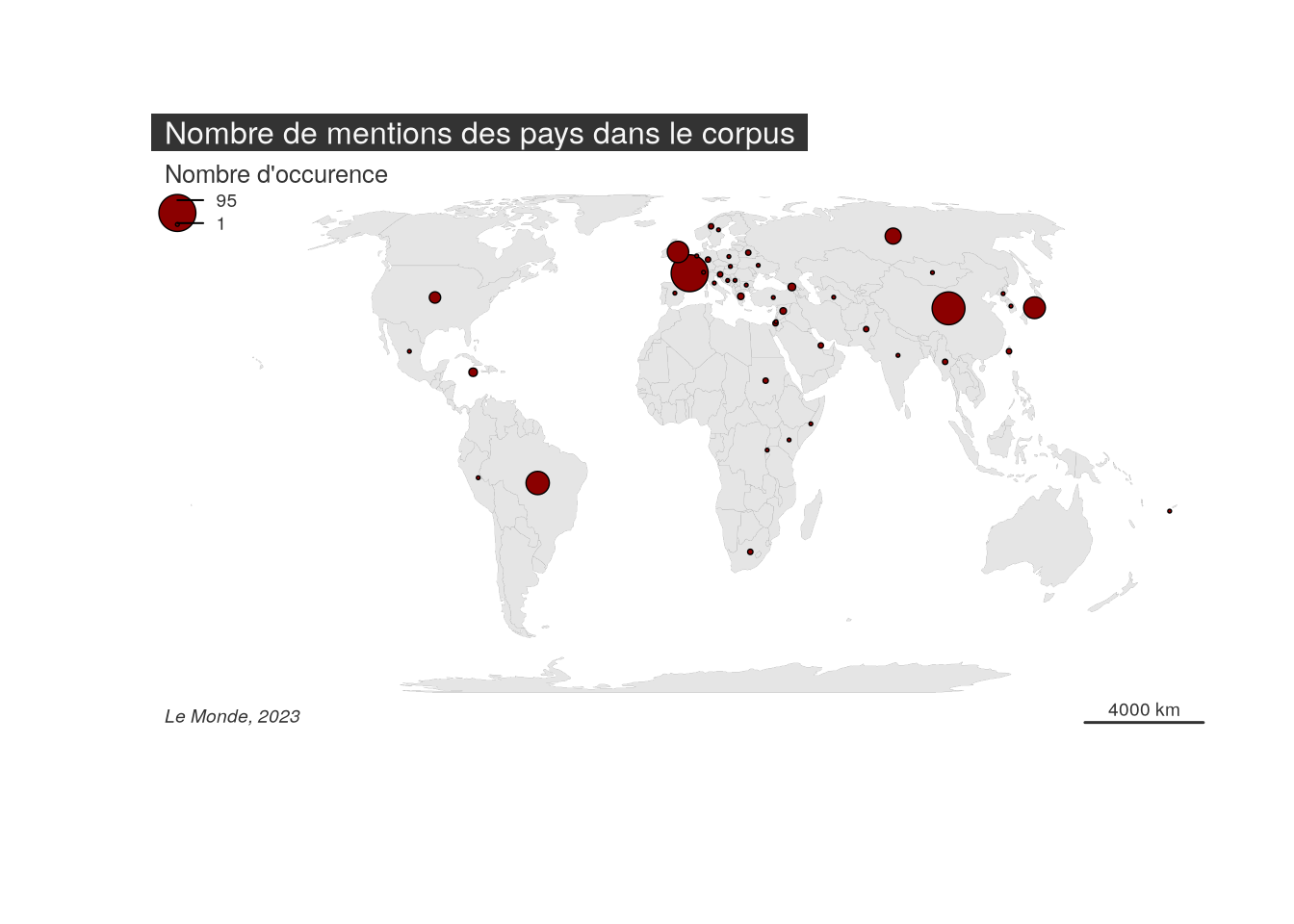
2.0.14.4 Exemple de cartogrpahie à partir d’une dfm de tags spatiaux
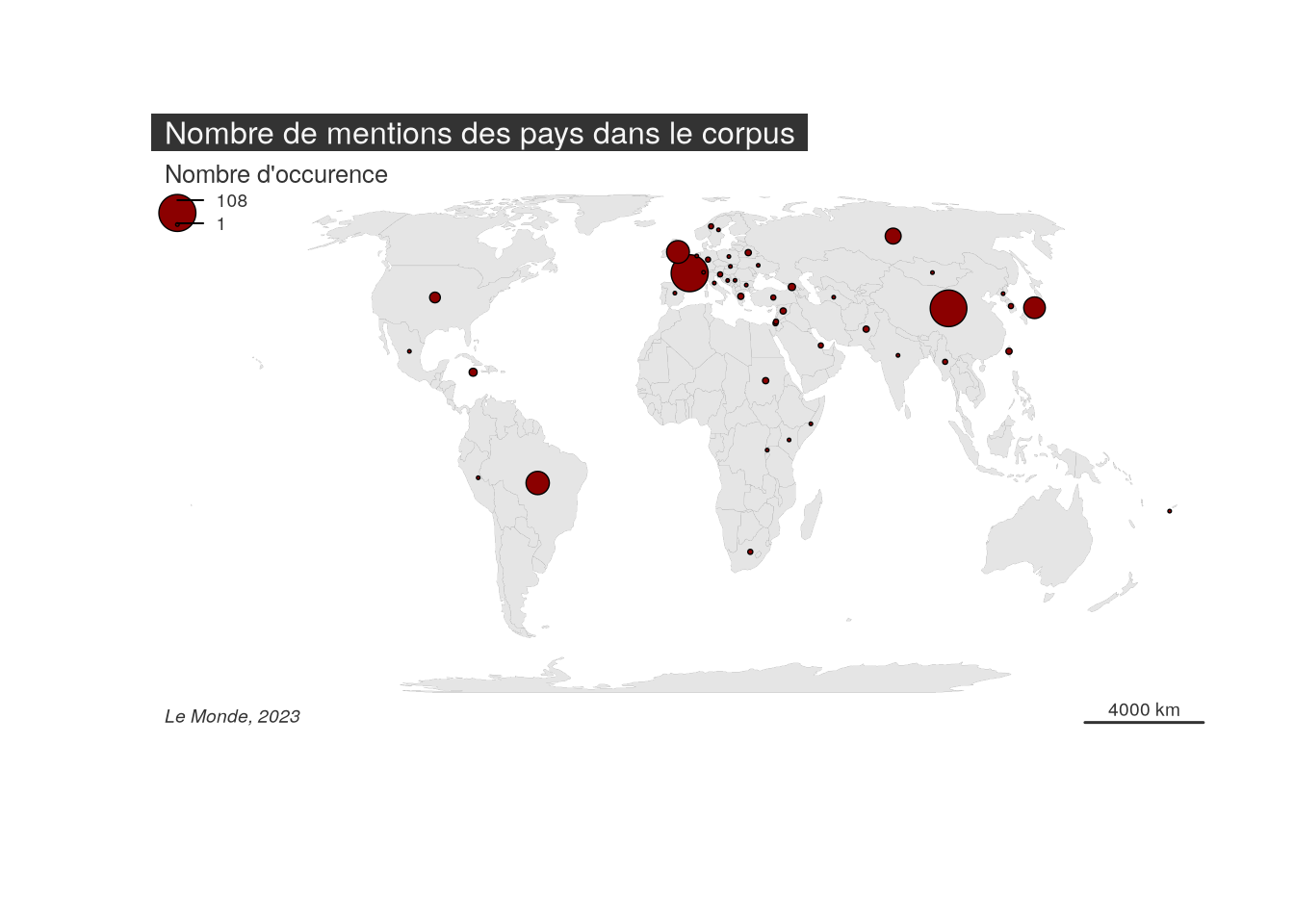
Dans la mesure où le newsmap utilise le code ISO2 des Etats dans son dictionnaire, il est possible de produire une carte thématique des occurences à partir de ce tableau. Il suffit de disposer d’un fond de carte du monde comportant un code ISO2 (ce qui peut se faire dans R via le package rnaturalearth et rnaturalearthdata, mais ce n’est pas l’objet de cette formation) et d’un module de cartographie thématique (comme mapsf).
Linking to GEOS 3.14.1, GDAL 3.12.2, PROJ 9.8.0; sf_use_s2() is TRUE
library(mapsf)# chargement du fond de carte des Etats du monde avec sfworld_map <-read_sf("FDC/EckertIV.shp")# jointurecountry_maps <-merge(world_map,df_freq, by.x="iso_a2_eh", by.y="feature")class(country_maps)
[1] "sf" "data.frame"
# tracé de du fond de carte avec plot et des cercles prop. avec mapsf plot(st_geometry(world_map),border="grey60",col="grey90",lwd=0.1)mf_prop(country_maps,inches=0.1,var="frequency", col="darkred",border="black",leg_pos ="topleft",leg_title ="Nombre d'occurence",add=T)mf_layout( title ="Nombre de mentions des pays dans le corpus",scale= T,arrow = F,credits ="Le Monde, 2023")
2e version avec un calcul de fréquence valant pour 1 pour les noms de pays apparaissant 1 fois ou plus.
# creation d'un tableau de fréquences avec 1 fréquence = au moins 1 occurencecountries_mat <-convert(dfm_countries,to="matrix")countries_mat <-ifelse(countries_mat>0,1,0)dfm_countries2 <-as.dfm(countries_mat)df_freq <-textstat_frequency(dfm_countries2)# jointurecountry_maps <-merge(world_map,df_freq, by.x="iso_a2_eh", by.y="feature")class(country_maps)
[1] "sf" "data.frame"
# tracé de du fond de carte avec plot et des cercles prop. avec mapsf plot(st_geometry(world_map),border="grey60",col="grey90",lwd=0.1)mf_prop(country_maps,inches=0.1,var="frequency", col="darkred",border="black",leg_pos ="topleft",leg_title ="Nombre d'occurence",add=T)mf_layout( title ="Nombre de mentions des pays dans le corpus",scale= T,arrow = F,credits ="Le Monde, 2023")
2.0.15 Enrichissement des données
Il est possible d’utiliser la dfm détectant les pays comme un simple tableau, qui peut servir à compléter les métadonnées du docvar. On vient de procède donc à un enrichissement de la base de données, qui intègre maintenant des variables associés à la détection des Etats.
La seule subtilité consiste à convertir la dfm en data.frame pour autoriser le collage ou la jointure des colonnes au tableau de docvars (en utilisant l’outil défié de quanteda, convert).
Avant d’opérer, on sélectionnera uniquement les Etats pour lesquels le nombre total d’occurences est supérieur à 5 avec la fonction dfm_trim(), qui permet de filtrer une dfm selon des seuils statistiques.
# filtrage de la dfm selon un seuil statistiquedfm_countries_sel <-dfm_trim(dfm_countries, min_termfreq =5)# transformation de la dfm en data.framecountries_df <-convert(dfm_countries_sel, to="data.frame")# collage des colonnesnew_docvars_df <-cbind(docvars(my_tokens_sel),countries_df)# assignation du nouveau df comme doc var de mon Tokensdocvars(my_tokens_sel) <- new_docvars_df
2.0.16 Sauvegarde au format RDS
Il est possible de sauvegarder les objets quanteda en les sauvegardant au format .RDS. Pour être identifié comme fichier au format quanteda et manipulé comme tel, le package doit être préalablement chargé (sinon il sera considéré comme une simple list).
# on utilise la fonction de base saveRDSsaveRDS(my_tokens_sel,"data/corpusJOannote.RDS")