La première modalité de collecte des données s’appuie sur des outils de l’institution ministérielle HCERES. En effet, il est possible de collecter directement un jeu de feuilles de calculs, doté de “macros” (voir Section 2.1) pour insérer des données complémentaires du laboratoire (équipes, doctorant⋅es).
Figure 3 : Dispositifs proposés d’accès aux données de production scientifique. a. auréHAL permet de naviguer au sein de 6 référentiels de l’archive HAL. Pour déterminer l’identifiant interne du laboratoire, remplir le champ du référentiel “Structures” avec l’acronyme ou l’intitulé du laboratoire par exemple. Choisir l’UMR IDEES dans la liste proposée. En cliquant sur “voir” , l’UMR IDEES est décrite dans son environnement institutionnel. Il est possible de saisir d’autres champs, comme par exemple pour une revue ou un⋅e auteur⋅ice. b. La plateforme MonÉvaluation d’accès aux données issues de HAL est proposée par le HCERES. Il est nécessaire de renseigner le formulaire pour collecter les données : ici, l’identifiant auréHAL de l’UMR IDEES est 97036 et la période concernée est 2020-2026. Le résultat est téléchargeable sous la forme d’un jeu de feuilles de calcul.
En poursuivant la navigation, il est alors possible d’obtenir la liste des notices de documents rattachées directement à l’UMR IDEES pour la période investiguée.
2.1 Méthode indirecte de collecte : “Microsoft Excel”
Préalables requis pour utiliser le notebook & coopération inter-laboratoire
Ce travail est issu d’une collaboration avec Marion Masonobe de Géographies-Cités. Pour l’utiliser, il est nécessaire d’avoir réalisé deux étapes préalables :
- télécharger le document .xlsm de la plateforme “MonÉvaluation”,
- renseigner la seconde feuille du tableur avec les données “locales” relatives au personnel du laboratoire et ses équipes,
- adapter les données du code pour jouer le document computationnel sur vos propres données, notamment le chemin du document source, le nom du laboratoire et sa structuration en équipes ou encore certains intitulés de colonnes du fichier .xlsm etc.
Ce document constitue la sources des opérations réalisées dans cette partie du document. Au moment de l’édition, ce document est daté du mercredi 27 mai 2026.
2.1.1 Personnel de recherche de l’UMR IDEES (2020-2026)
Un extrait de la liste du personnel de recherche, permanent ou contractuel, par axe, connu sur l’archive HAL est donné dans la table ci-dessous.
Code
# lire un document MS Excelrequire(readxl)require(tidyverse)require(kableExtra)source <-"./data/HAL-PRODUCTION-97036_v10022026.xlsm"unitname <-"IDEES UMR CNRS 6266"# création de documents intermédiaires & dossiers associésmap(c("data", "figures", "tables", "stats"), dir.create)# collecte et inscription des données relatives aux équipesstaff <-read_excel(source, sheet =2, skip =11)staff <- staff[, 1:3] %>%set_names(slice(.,1)) %>%slice(-1) %>%mutate(statut ="permanent") %>%bind_rows(staff[, 5:7] %>%set_names(slice(.,1)) %>%slice(-1) %>%mutate(statut ="doctorant")) %>%rename(equipe =`Nom de l'équipe interne`) %>%drop_na()# écriture des données dans le fichierwrite_tsv(staff, "data/staff.tsv")# enregistrement des tablesrequire(webshot2)#- extrait en pngtbl_staff <- staff[sample(nrow(staff),15),] %>%select(-statut) %>%kbl(col.names =NULL, caption ="Table 1 : Extrait aléatoire de la liste des membres de l'UMR et leur affectation thématique.") %>%add_header_above(c("Nom", "Prénom","Axe principal")) %>%kable_styling(full_width = T)tbl_staff %>%save_kable("tables/extrait_staff.png")#- ensemble en pdf imprimablestaff[order(staff$Nom),] %>%select(-statut) %>%kbl(col.names =NULL, longtable = T, booktabs = T) %>%add_header_above(c("Nom", "Prénom","Axe principal")) %>%# kable_classic(full_width = F) %>%kable_styling(latex_options =c("repeat_header")) %>%# column_spec(1) %>% save_kable("tables/total_staff.pdf")
Nom
Prénom
Axe principal
Table 1 : Extrait aléatoire de la liste des membres de l’UMR et leur affectation thématique.
ABARAGH
Brahim
Axe 4
JOSEPH
Camille
Axe 4
NIAT TOUNDJI TCHATCHOUA
Julien
Axe 1
CUYPERS
Inès
Axe 4
GAILLARD
David
Axe 3
BLANCHARD
Nicolas
Axe 2
BARZMAN
John
Axe 3
VIBERT
Patrice
Axe 4
TAPSOBA
Boureima
Axe 4
MICHEL
Bastien
Axe 3
LECOQUIERRE
Bruno
Axe 4
LEGRAND
Emilie
Axe 4
MATHOU
François
Axe 4
LIENARD
Fabien
Axe 4
SANDBERG
Bastien
Axe 2
2.1.2 Sélection de types de documents
Parmi l’ensemble des productions scientifiques (voir le tableau 1.1 dans la note 1.1), l’étude limite le corpus des publications aux types suivants : article à comité de lecture, conférence, actes de colloques, numéro spécial de revue, ouvrage, chapitre d’ouvrage.
D’autres types peuvent être pris en compte, le cas échéant.
Code
require(readxl)require(tidyverse)require(kableExtra)# collecte de la liste des ACLarticle <-read_excel(source, sheet =3, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de l'article`, `Nom de la revue`, `Revue à comité de lecture`) %>%# mutate(type = "article", audience = NA, publisher = NA) %>%mutate(type ="article") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`, TI =`Titre de l'article`,SO =`Nom de la revue`,peereviewed =`Revue à comité de lecture`)# collecte de la liste des communicationsconf <-read_excel(source, sheet =4, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la communication`, `Titre du congrès`, Audience) %>%# mutate(type = "conf", peereviewed = NA, publisher = NA) %>%mutate(type ="conf") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la communication`,SO =`Titre du congrès`,audience = Audience) %>%drop_na(AU)# collecte de la liste des actesactes <-read_excel(source, sheet =6, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la publication`, `Titre du volume`) %>%# mutate(type = "actes", peereviewed = NA, publisher = NA, audience = NA) %>%mutate(type ="actes") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la publication`,SO =`Titre du volume`)# collecte de la liste des numéros spéciauxnspecial <-read_excel(source, sheet =7, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la publication`, `Titre du volume`) %>%# mutate(type = "nspecial", peereviewed = NA, publisher = NA, audience = NA) %>%mutate(type ="nspecial") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la publication`,SO =`Titre du volume`)# collecte de la liste des ouvragesbook <-read_excel(source, sheet =8, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de l'ouvrage`, Editeur) %>%# mutate(type = "book", SO = NA, peereviewed = NA, audience = NA) %>%mutate(type ="book") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de l'ouvrage`, publisher = Editeur)# collecte de la liste des chapitres d'ouvrageschapter <-read_excel(source, sheet =9, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre du chapitre dʹouvrage`, `Titre de l'ouvrage`, Editeur) %>%# mutate(type = "chapter", peereviewed = NA, audience = NA) %>%mutate(type ="chapter") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre du chapitre dʹouvrage`,SO =`Titre de l'ouvrage`, publisher = Editeur)# inscriptions de la liste des documents sélectionnéslibrary(purrr)# fusion des listespub <-bind_rows(actes, article, book, chapter, conf)ncorr <-is.na(pub$equipe) %>%sum(na.rm =TRUE)npub <-nrow(pub)# inscription des données write_tsv(pub, "data/umr_selection.tsv")# production des tables et création de fichiers imagesrequire(webshot2)#- extrait pngtbl_pub <- pub[sample(nrow(pub),15),] %>%select(PY,AU,TI,equipe,halid) %>%kbl(col.names =NULL, caption ="Table 2 : Extrait aléatoire de la liste des documents issu de la production scientifique de l'UMR, précisant l'année de publication, les auteur⋅ices, le titre, l'axe thématique et le n°HAL de la notice HAL.") %>%add_header_above(c("Année", "Auteur/trices","Titre","Axes", "n°HAL")) %>%kable_styling(full_width = T) tbl_pub %>%save_kable("tables/extrait_pub.png")#- ensemble des données en pdf imprimablepub[order(pub$AU),] %>%select(PY,AU,TI,equipe,halid) %>%kbl(col.names =NULL, longtable = T, booktabs = T) %>%add_header_above(c("Année", "Auteur/trices","Titre","Axes", "n°HAL")) %>%# kable_classic(full_width = F) %>%kable_styling(latex_options =c("repeat_header")) %>%# column_spec(1) %>% save_kable("tables/total_pub.pdf")
Au sein du corpus, 6.97% des notices (soit 64 notices) semblent n’être pas associées aux membres du laboratoire attachés à ses axes : des corrections manuelles sont nécessaires (inversion nom/prénom, faux positif etc.).
Année
Auteur/trices
Titre
Axes
n°HAL
Table 2 : Extrait aléatoire de la liste des documents issu de la production scientifique de l’UMR, précisant l’année de publication, les auteur⋅ices, le titre, l’axe thématique et le n°HAL de la notice HAL.
2025
HUCY W., JENNEQUIN H.
Dynamiques de construction et de structuration des parcours d’orientation postbac face aux inégalités d’origines socioterritoriales et de motilité des élèves de lycée général
Axe 4
https://hal.science/hal-05324396
2021
VAGUET Y.
Fronts et frontières en Arctique, quelle singularité ?
Axe 3
https://hal.science/hal-03477474
2024
BANOS A., VIVES L., MARTEL C., HESSEK E., WILLIAMS K.
Lorsque le contrôle des migrations prend le pas sur la sauvegarde de la vie en mer
Axe 1 ; Axe 3
https://hal.science/hal-04815257
2022
FORLEN M.
Quels dispositifs filmiques pour enquêter la question de l’habiter des travailleur-euses mobiles dans les Zones Économiques Spéciales (ZES) ?
Axe 4
https://hal.science/hal-04982149
2023
JAILLET S., AUDIN L., BUJAN S., CAZES G., COUILLET A., HONIAT A., LOPEZ S., MONVOISIN G., QUENAULT B., ROBERT X.
Drones souterrains, inspection et imagerie 3D : contraintes et potentialités d’un nouvel outil de documentation des grottes et du karst
Axe 1
https://hal.science/hal-04394455
2024
GUILLEMOIS M., DELAHAYE D., REULIER R.
Évolution des trajectoires paysagères et des connectivités hydrologiques dans deux bassins versants bocagers normands depuis deux siècles
Axe 1
https://hal.science/hal-04605084
2023
KLEIN J.-F., DREMEAUX F., VAISSET T.
Une mise en connexion du monde : paquebots et grandes lignes maritimes, XIXe-XXe siècles : introduction
Axe 3
https://hal.science/hal-04943120
2021
DAUDE E., GRANCHER D., LAVIGNE F.
Évacuation massive des populations en temps d’épidémie de COVID-19 : comment éviter la sur-crise ?
Axe 4
https://hal.science/halshs-03177723
2021
NATHAN G.
La faiblesse des fonctions métropolitaines dans les grandes villes périphériques du Bassin parisien
NA
https://hal.science/hal-03542742
2025
HOCHEDEZ C., BERTHOMIERE W., IMBERT C., PISTRE P.
Les lifestyle farmers étrangers, des trajectoires d’installation entre mobilisation des privilèges et valorisation de la précarité. Regards depuis les campagnes du Sud -Ouest français (Ariège, Dordogne)
Axe 4
https://hal.science/hal-05262717
2020
COTTINEAU C., CHAPRON P., TEXIER M. L., REY-COYREHOURCQ S.
Modélisation territoriale incrémentale
Axe 1
https://hal.science/hal-02285662
2021
AMAT F., IMBERT C., LE ROUX G.
La métropolisation au regard de la restructuration des catégories socioprofessionnelles: tertiarisation de l’emploi et spécialisations sociales (1968-2015)
Axe 4
https://hal.science/hal-03457640
2024
ERNE-HEINTZ V.
Du care dans le système alimentaire ou comment le sensible transforme les liens entre alimentation et agriculture
Axe 2
https://hal.science/hal-05318394
2024
CHAIZE B., FRESSARD M., CHRISTOL A., COSSART E.
Analyse spatio-temporelle de l’érosion des sols dans un bassin versant viticole (Mercurey, Bourgogne)
Axe 2
https://hal.science/hal-05464163
2021
SERRY A., KERBIRIOU R.
Estimation of polluting emissions of chips calling in the major Belgian ports in 2019
Axe 3
https://hal.science/hal-03225779
2.2 Premiers éléments d’analyse des données collectées par la méthode indirecte
2.2.1 Types de documents retenus pour l’analyse
Code
library(tidyverse)# selection des documents avec peereviewpub <-read_tsv("data/umr_selection.tsv") %>%filter(! peereviewed %in%"N") %>%rowid_to_column("ID")# inscription des classes type de document et de leur populationpub %>%count(type) %>%arrange(-n) %>%write_tsv("stats/type.tsv")
Code
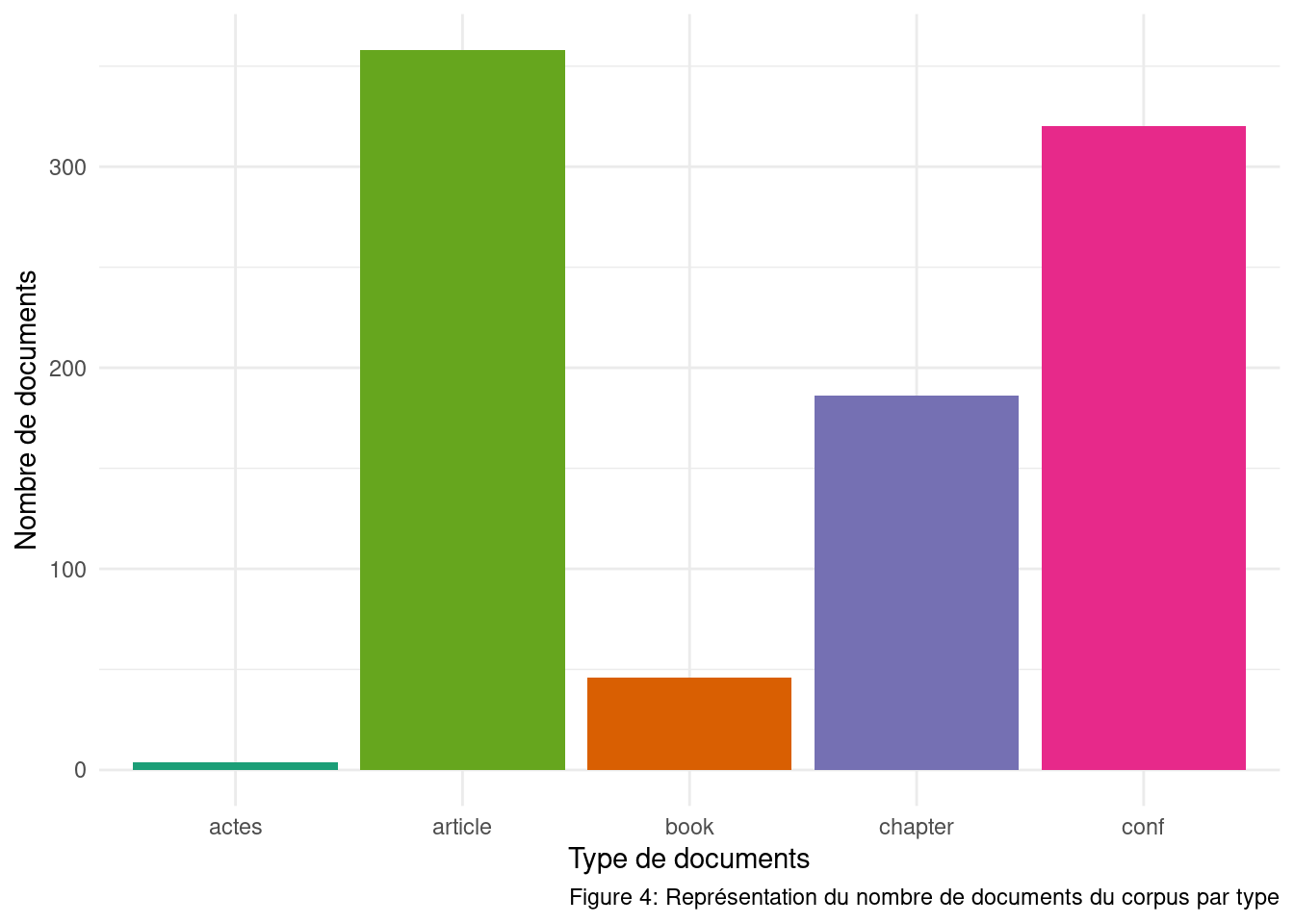
require(readr)require(ggplot2)type_pub <-read_tsv("stats/type.tsv")ggplot(type_pub, aes(x = type, y = n)) +geom_bar(stat ="identity",fill =c("#66a61e","#e7298a","#7570b3","#d95f02","#1b9e77"))+xlab("Type de documents") +ylab("Nombre de documents") +labs(caption ="Figure 4: Représentation du nombre de documents du corpus par type") +theme_minimal() +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969"))
Code
# +# theme_minimal()ggsave("figures/type.png")
2.2.2 Pratiques de publications des équipes : co-authoring
Code
library(tidyverse)library(stringi)# créé une sous-liste des co-auteurices de pub$AUT## motif/pattern de sous catégorisation des auteuricesmotif_aut <-";\\\n|, "split_aut <-function(x) {str_split(x, motif_aut) %>% purrr::map(str_subset, "\\w+")} ## sous catégorisation des co-auteuricespub$aut <- pub$AU %>%split_aut()# créé une sous-liste des équipes de pub$equipe## motif/pattern de sous catégorisation des équipes (il y en a 4)motif_equ <-" ; |; |; |;"split_equ <-function(x) {str_split(x, motif_equ) %>% purrr::map(str_subset, "\\w+")} ## sous catégorisation des équipespub$equ <- pub$equipe %>%split_equ()# créé une colonne du nombre d'auteurices par documentpub <- pub %>% rowwise %>%mutate(nbaut =length(aut)) # nombre de co-auteurices par publication par équipepub %>%unnest(equ) %>%group_by(equ) %>%# groupe par équipesummarise(n =n_distinct(ID), ncoaut =n_distinct(ID[nbaut >1]),mean_coaut =mean(nbaut)) %>%# moyenne nbre auteuricesmutate(coaut = ncoaut/n*100) %>%bind_rows(pub %>%count(equ ="Total", ncoaut =n_distinct(ID[nbaut >1]), mean_coaut =mean(nbaut)) %>%mutate(coaut = ncoaut/n*100)) %>%write_tsv("stats/coaut.tsv")
Code
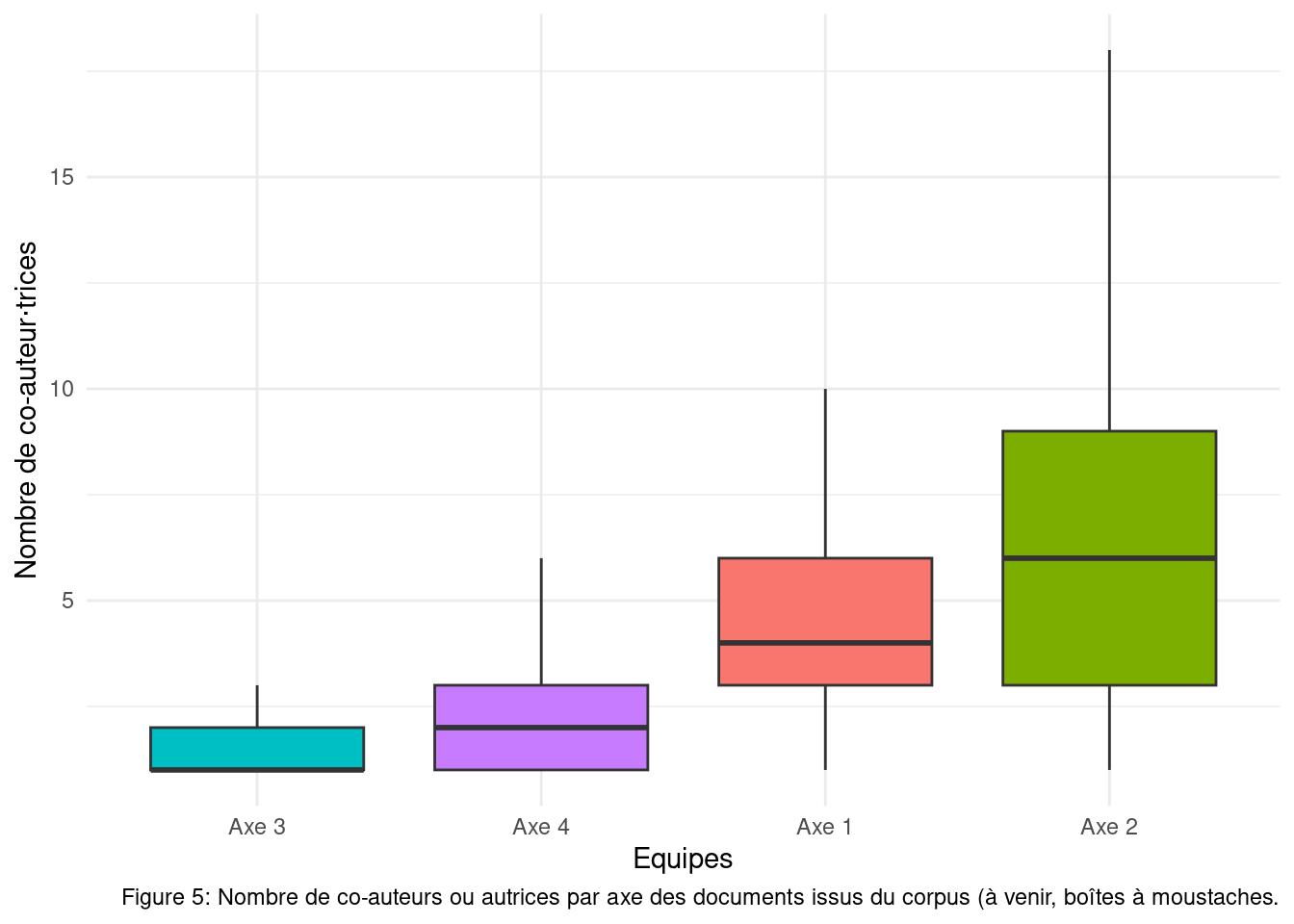
library(ggplot2)library(scales)require(readr)coaut_equi <-read_tsv("stats/coaut.tsv")# ggplot(coaut_equi, aes(x = equ, y = mean_coaut, fill = coaut)) +# geom_bar(stat = "identity") +# xlab("Équipes") +# ylab("Nombre moyen de co-auteur⋅rices") +# labs(caption = "Figure 5: Nombre de co-auteurs ou autrices par axe des documents issus du corpus (à venir, boîtes à moustaches.") +# theme_minimal() +# guides(fill = guide_legend(title = "% documents\n avec co-auteur⋅\nrices", reverse=T)) +# scale_fill_continuous(high = "#132B43", low = "#56B1F7")coautequ <- pub %>%unnest(equ) %>%select(equ,nbaut)ggplot(coautequ, mapping =aes(x =reorder(equ,nbaut), y = nbaut, fill = equ)) +geom_boxplot(outliers =FALSE) +xlab("Equipes") +ylab("Nombre de co-auteur⋅trices") +labs(caption ="Figure 5: Nombre de co-auteurs ou autrices par axe des documents issus du corpus.") +theme_minimal() +theme(legend.position="none",plot.caption =element_text(hjust =0.5, size =11, colour ="#696969"))
Code
ggsave("figures/coaut_equi.png")
2.2.3 Publications inter-équipes
Code
# créé une colonne du nombre d'équipes par documentpub <- pub %>% rowwise %>%mutate(nbequipe =length(equ)) # nombre de documents partagés par plus d'une équipepub %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncol =n_distinct(ID[nbequipe >1])) %>%mutate(intereq = ncol/n*100) %>%bind_rows(pub %>%filter(nbaut >1) %>%count(equ ="Total", ncol =n_distinct(ID[nbequipe >1])) %>%mutate(intereq = ncol/n*100)) %>%write_tsv("stats/coequ.tsv")
Code
library(ggplot2)library(knitr)library(kableExtra)co_equ <-read_tsv("stats/coequ.tsv")tbl_co_equ <- co_equ %>%select(equ, intereq) %>%mutate(intereq =round(intereq, 1)) %>%pivot_wider(names_from = equ, values_from = intereq) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 3: Co-production scientifique inter-équipes en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production inter-équipes pour chaque équipe"=4)) %>%kable_styling(full_width = T)tbl_co_equ %>%save_kable("tables/copub_equi.png")
Table 3: Co-production scientifique inter-équipes en pourcentage (%) pour chaque équipe à partir des documents du corpus.
Pourcentage (%) de co-production inter-équipes pour chaque équipe
Période
Axe 1
Axe 2
Axe 3
Axe 4
2020-2026
48.8
15
19.3
16.1
Code
library(igraph)el <- pub %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(npub =n_distinct(ID)) %>%unnest_wider(equ, names_sep =" ") %>%rename(i =`equ 1`, j =`equ 2`, k =`equ 3`) %>%drop_na(i) %>%select(i, j, npub) %>%# warning, the only publi involving the 3 teams is removed (??)mutate(j =ifelse(is.na(j), i, j)) %>%drop_na()g <-graph_from_data_frame(el, directed = F, vertices =c("Axe 1","Axe 2","Axe 3","Axe 4"))g <-simplify(g, remove.loops = F, edge.attr.comb ="sum")#mat <- as_adjacency_matrix(g, type = "upper", attr = "npub", sparse = F)mat <-as_adjacency_matrix(g, attr ="npub", sparse = F)mat <- mat/colSums(mat)*100write_rds(mat, "stats/mat.rds")write(data.matrix(mat), "stats/mat.tsv")
Code
require(gdata)mat <-read_rds("stats/mat.rds")mat <-round(mat, 1)lowerTriangle(mat) <-""mat_co_equ <- mat %>%kbl(booktabs = T, caption ="Table 4: Matrice de répartition de la co-production scientifique (en pourcentage %) entre les équipes à partir des documents du corpus.") %>%add_header_above(c(" ", "Répartition en % de co-production entre les équipes"=4)) %>%kable_styling(full_width = T)mat_co_equ %>%save_kable("tables/mat_copub_equi.png")
Table 4: Matrice de répartition de la co-production scientifique (en pourcentage %) entre les équipes à partir des documents du corpus.
Répartition en % de co-production entre les équipes
Axe 1
Axe 2
Axe 3
Axe 4
Axe 1
51.2
14
14.9
19.8
Axe 2
86.8
0.7
0.7
Axe 3
80.7
5.7
Axe 4
83.9
2.2.4 Co-publications avec des extérieur⋅es
Code
require(ggplot2)require(knitr)require(tidyr)# créé une colonne réduite des (nom & initiale prénom) de membres du labostaff <- staff %>%distinct(Nom, Prénom, statut) %>%mutate(initial =str_remove_all(Prénom, "[:lower:]") %>%str_remove_all("\\.") %>%str_remove_all("\\s$"),autc =str_c(str_to_upper(Nom), " ", initial)) %>%distinct(autc, .keep_all = T)# fait une jointure entre la liste des publications & les auteur⋅ices labomatch <- pub %>%unnest(aut) %>%mutate(aut =trimws(aut)) %>%mutate(autc =str_remove_all(aut, "\\.") %>%trimws()) %>%left_join(staff, by ="autc")# ID lignes des auteur∕ices extérieur⋅eshalidautres <- match %>%filter(is.na(Nom)) %>%pull(ID) # ajout d'une colonne ext TRUE si l'auteur⋅ice est extérieurpub <- pub %>%mutate(ext =ifelse(ID %in% halidautres, T, F))# compte la part de co-auteurices extérieur⋅es & le nbre de pub associéespub %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncoext =n_distinct(ID[ext == T])) %>%mutate(coext = ncoext/n*100) %>%bind_rows(pub %>%filter(nbaut >1) %>%count(equ ="Total", ncoext =n_distinct(ID[ext == T])) %>%mutate(coext = ncoext/n*100)) %>%write_tsv("stats/coext.tsv")
Code
library(ggplot2)library(knitr)library(kableExtra)coext <-read_tsv("stats/coext.tsv")tbl_co_ext <- coext %>%select(equ, coext) %>%mutate(coext =round(coext, 1)) %>%pivot_wider(names_from = equ, values_from = coext) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 5: Co-production scientifique avec des extérieur⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production avec des extérieur⋅es pour chaque équipe."=4)) %>%kable_styling(full_width = T)tbl_co_ext %>%save_kable("tables/tbl_copub_ext.png")
Table 5: Co-production scientifique avec des extérieur⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.
Pourcentage (%) de co-production avec des extérieur⋅es pour chaque équipe.
Période
Axe 1
Axe 2
Axe 3
Axe 4
2020-2026
77.7
95.9
69.3
88.3
2.2.5 Co-publications avec les doctorant⋅es
Code
library(ggplot2)library(knitr)library(tidyr)# ID lignes des auteur∕ices doctorant⋅esdoct <- match %>%filter(statut =="doctorant") %>%pull(ID) # ajout d'une colonne doct TRUE si l'auteur⋅ice est doctorantpub_co_aut <- pub %>%filter(nbaut >1) %>%mutate(audoct =ifelse(ID %in% doct, T, F))# compte la part de co-auteurices doctorant⋅es & le nbre de pub associéespub_co_aut %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncodoct =n_distinct(ID[audoct == T])) %>%mutate(codoct = ncodoct/n*100) %>%bind_rows(pub_co_aut %>%# filter(nbaut > 1) %>%count(equ ="Total", ncodoct =n_distinct(ID[audoct == T])) %>%mutate(codoct = ncodoct/n*100)) %>%write_tsv("stats/codoct.tsv")
Code
library(ggplot2)library(knitr)library(kableExtra)codoct <-read_tsv("stats/codoct.tsv")tbl_co_doct <- codoct %>%select(equ, codoct) %>%mutate(codoct =round(codoct, 1)) %>%pivot_wider(names_from = equ, values_from = codoct) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 6: Co-production scientifique avec les doctorant⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production avec des doctorant⋅es"=4)) %>%kable_styling(full_width = F)tbl_co_doct %>%save_kable("tables/tbl_copub_doct.png")
Table 6: Co-production scientifique avec les doctorant⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.
Pourcentage (%) de co-production avec des doctorant⋅es
Période
Axe 1
Axe 2
Axe 3
Axe 4
2020-2026
38
23.1
22.1
16.6
2.2.6 Langues de publication
Code
# sélectionner la variable "langue de publication", puis mesurer le nombre ainsi que le pourcentage d'articles par langue et par périodelang <- pub %>%unnest(equ) %>%mutate(langue =str_to_lower(langue)) %>%# mutate(langue = ifelse(langue %in% "anglais, espagnol", "espagnol", langue)) %>%filter(langue %in%c("anglais", "français", "espagnol")) %>%group_by(equ, langue) %>%# grouper les données par période et par langue de publication# créer un nouveau tableau indiquant le nombre d'articles par equipe et par languesummarise(n =n()) %>%mutate(prct =round(n/sum(n)*100, 1)) %>%# ajouter une colonne avec le % d'articles par langue à chaque equipepivot_wider(names_from = equ, values_from =c(n, prct)) %>%# transposer le tableau en largeurmutate(across(everything(), ~replace_na(.x, 0))) %>%# remplacer les valeurs manquantes par des zerosmutate(total_nb =rowSums(across(starts_with("n")))) %>%# ajouter une colonne avec le total des 3 equipemutate(total_prct =round(total_nb/sum(total_nb)*100, 1)) %>%# ajouter une colonne avec le % du totalarrange(-total_nb) %>%relocate(`prct_Axe 1`, .before =3) %>%# modifier la position de la colonne prct_p1relocate(`prct_Axe 2`, .before =5) %>%# modifier la position de la colonne prct_p2 etcrelocate(`prct_Axe 3`, .before =7)write_tsv(lang, "stats/lang.tsv")
Code
lang <-read_tsv("stats/lang.tsv")tbl_langues <- lang %>%bind_rows(summarise(., # ajouter les totaux par colonneacross(where(is.numeric), \(x) sum(x)), # faire le total pour les colonnes numériquesacross(where(is.character), ~"Total")) %>%# écrire "Total" dans la première colonnemutate(across(contains("prct"), round, 1))) %>%# arrondir les nombres obtenus pour les %kbl(booktabs = T, caption ="Table 7: Répartition par langues (en nombre et en %) de la production scientifique pour chaque équipe à partir des documents du corpus.", col.names =NULL) %>%# représenter le contenu du tableau sauf les entêtes de colonnes# ajouter une première entête de colonne pour chacune des 9 colonnes du tableauadd_header_above(c("Langue", rep(c("Nb", "%"), 5))) %>%# ajouter une seconde entête surplombant la première, indiquant les 3 périodes et la partie Totaladd_header_above(c(" ", "Axe 1"=2, "Axe 2"=2, "Axe 3"=2, "Axe 4"=2, "Total"=2)) %>%# ajouter une troisième entête générale précisant le contenu d'ensemble du tableauadd_header_above(c(" ", "Répartition par équipe des langues de publication et communication par équipe."=10)) %>%kable_styling(full_width = F) %>%# choisir l'apparence du tableau et la policerow_spec(dim(lang)[1]+1, bold = T) %>%# mettre en gras la dernière ligne (totaux en ligne)column_spec(c(3, 5, 7, 9, 11), italic = T)tbl_langues %>%save_kable("tables/tbl_langues_pub.png")
Répartition par équipe des langues de publication et communication par équipe.
Axe 1
Axe 2
Axe 3
Axe 4
Total
Langue
Nb
%
Nb
%
Nb
%
Nb
%
Nb
%
Table 7: Répartition par langues (en nombre et en %) de la production scientifique pour chaque équipe à partir des documents du corpus.
français
58
45
78
44.3
188
65.7
194
59.3
518
56.4
anglais
71
55
98
55.7
98
34.3
129
39.4
396
43.1
espagnol
0
0
0
0.0
0
0.0
4
1.2
4
0.4
Total
129
100
176
100.0
286
100.0
327
99.9
918
99.9
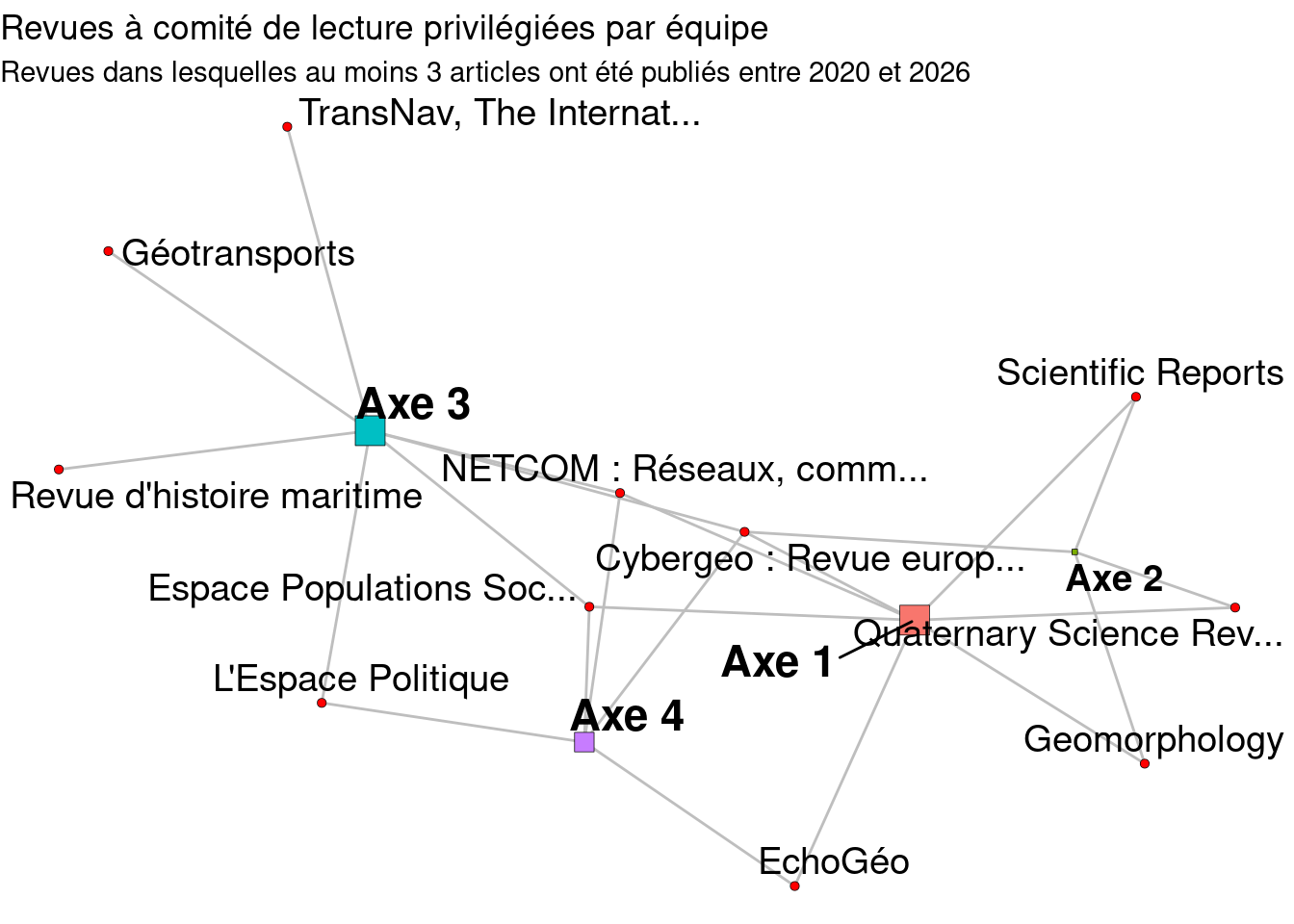
2.2.7 Graphe des revues & équipes
Code
# collecte des revues par équipebip <- pub %>%filter(type %in%"article") %>%unnest(equ) %>%group_by(halid) %>%mutate(id =paste0("A", cur_group_id())) %>%ungroup() %>%distinct(id, SO, equ)# revues les plus fréquencestop <- bip %>%group_by(SO) %>%summarise(n =n_distinct(id)) %>%arrange(-n) %>%filter(n >3) %>%# & ! SO %in% "The Conversation"pull(SO)# association revues vs équipesbip <- bip %>%filter(SO %in% top) %>%distinct(equ, SO)# tableau équipe intermédiaireattr <- bip %>%distinct(equ) %>%rename(node = equ) %>%mutate(type ="equipe") # tableau des revuesso <-distinct(bip, SO) %>%mutate(type ="journal") %>%rename(node = SO)# inscriptionwrite_tsv(so, "data/so_rev.tsv")
Code
# construction des noeudsrequire(dplyr)require(stringr)so <-read_tsv("data/so_rev.tsv")v <-bind_rows(attr, so) %>%mutate(col =case_when(node %in%"Axe 1"~"forestgreen", node %in%"Axe 2"~"blue", node %in%"Axe 3"~"purple", node %in%"Axe 4"~"gold",TRUE~"grey"))# construction des classesbipi <- bip %>%left_join(so, by =c("SO"="node")) %>%distinct(SO, equ, type) %>%relocate(SO, 1)# construction des relationsv <-distinct(v, node, type, col)# construction du grapheslibrary(igraph)g <-graph_from_data_frame(bipi, directed = F, vertices = v)# symboliser les évènements par des carrés et les individus par des cerclesV(g)[V(g)$type %in%"journal"]$shape <-"square"V(g)[!V(g)$type %in%"journal"]$shape <-"circle"# choisir deux gammes de couleur pour bien distinguer les deux ensembles de sommetsV(g)$color <- v$col[match(V(g)$name, v$node)]V(g)$label <-ifelse(V(g)$shape %in%"square", str_trunc(V(g)$name, 14), NA)l <-layout_with_fr(g)# library(ggplot2)library(tidygraph)library(ggraph)g %>%ggraph(layout ="fr") +geom_edge_link(edge_colour ="grey") +geom_node_point(aes(filter = type %in%"journal"), show.legend = F, shape =21, fill ="red", stroke =0.2) +geom_node_point(aes(filter =! type %in%"journal", size =degree(g), fill = name), show.legend = F, shape =22, stroke =0.2) +geom_node_text(aes(label =ifelse(type %in%"journal", str_trunc(name, 25), name), fontface =ifelse(! type %in%"journal", "bold", "plain"),size =ifelse(! type %in%"journal", ifelse(degree(g) >=5, 11,8),6)),# size = ifelse(degree(g) >= 5, 7, 6)), colour ="black", repel = T, show.legend = F) +# size = ifelse(degree(g) >= 5, 7, 6)), colour = "black", repel = T, show.legend = F) + # , repel = TRUE, min.segment.length = Inf, max.overlaps = Inftheme_void() +scale_size(guide="none") +labs(fill =c("Equipe"),# title = "Revues à comité de lecture privilégiées par équipe",caption ="Figure 6: Revues dans lesquelles au moins 3 articles ont été publiés entre 2020 et 2026") +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969"))
2.3 Première synthèse
358 articles dans des revues ACL ont été publiés entre 2020 et 2026.
Les publications à plus d’un⋅e auteur⋅rice représentent 63.9% des publications. Publier seul⋅e est donc une pratique très minoritaire pour les équipes des axes 1 et 2, resp. 6.2% et 16.9% des publications, elle est partagée au sein des équipes des axes 3 et 4, resp. 51.2% et 37.7%.
Parmi les co-publications, 87% associent au moins un⋅e auteur⋅rice extérieur⋅e à l’UMR IDEES et 17.8% associent au moins un⋅e doctorant⋅e.
43.1% des publications sont en anglais.
2.4 Éléments critiques
Cette méthode de collecte des données de production scientifique du laboratoire est centrée sur le relevé de notices hal renseignées et rattachées à l’UMR IDEES (voir figure 1.2) exploitant une relation de type notice de document (halId) -> laboratoire (structure_t) au sein d’un dispositif fermé.
La suite de l’étude propose la construction d’un dispositif ouvert mobilisant notamment l’API HAL. Elle s’intéresse en particulier aux auteur⋅rices scientfiiques et leur rôle dans les notices d’oeuvres issues de la production scientifique.
Source Code
```{r}#| label: "common"#| include: FALSEsource("_common.R")```# auréHAL & MonÉvaluation {#sec-mon-evaluation-hceres}La première modalité de collecte des données s'appuie sur des outils de l'institution ministérielle HCERES. En effet, il est possible de collecter directement un jeu de feuilles de calculs, doté de "macros" (voir Section [-@sec-ms-excel]) pour insérer des données complémentaires du laboratoire (équipes, doctorant⋅es). ::: {.columns}::: {.column width="50%"}<iframe src="https://aurehal.archives-ouvertes.fr/" width="95%" height="500px" title="a) auréHAL" allowfullscreen="true" style="border:1px solid black;padding:5px;margin:5px;"></iframe>:::::: {.column width="50%"}<iframe src="https://monevaluation.hceres.fr/hal" width="95%" height="500px" title="b) Mon évaluation HCERES" style="border:1px solid black;padding:5px;margin:5px;"></iframe>::::::<figure><figcaption>Figure 3 : Dispositifs proposés d'accès aux données de production scientifique. <br> a. **auréHAL** permet de naviguer au sein de 6 référentiels de l'archive HAL. Pour déterminer l'identifiant interne du laboratoire, remplir le champ du référentiel "Structures" avec l'acronyme ou l'intitulé du laboratoire par exemple. Choisir l'UMR IDEES dans la liste proposée. En cliquant sur "voir" [<img src="/img/eye-svgrepo-com.svg" height="20px">](https://aurehal.archives-ouvertes.fr/structure/read/id/97036), l'UMR IDEES est décrite dans son environnement institutionnel. Il est possible de saisir d'autres champs, comme par exemple pour une revue ou un⋅e auteur⋅ice. <br> b. La plateforme **MonÉvaluation** d'accès aux données issues de HAL est proposée par le HCERES. Il est nécessaire de renseigner le formulaire pour collecter les données : ici, l'identifiant auréHAL de l'UMR IDEES est `97036` et la période concernée est 2020-2026. Le résultat est téléchargeable sous la forme d'un jeu de feuilles de calcul.</figcaption></figure>> En poursuivant la navigation, il est alors possible d'obtenir la [liste des notices](https://hal.science/search/index/?q=structId_i:(97036)+producedDateY_i:[2020+TO+2026]&sort=producedDateY_i%20desc&submit=&docType_s=ART+OR+COMM+OR+POSTER+OR+OUV+OR+COUV+OR+DOUV+OR+PATENT+OR+OTHER+OR+UNDEFINED+OR+REPORT+OR+CREPORT+OR+THESE+OR+HDR+OR+LECTURE+OR+MEM+OR+VIDEO+OR+SON+OR+IMG+OR+MAP+OR+SOFTWARE&submitType_s=notice+OR+file+OR+annex&rows=300) de documents rattachées directement à l'UMR IDEES pour la période investiguée.## Méthode indirecte de collecte : "Microsoft Excel" {#sec-ms-excel}:::{.callout-warning collapse="true"}## Préalables requis pour utiliser le *notebook* & coopération inter-laboratoireCe travail est issu d'une collaboration avec Marion Masonobe de Géographies-Cités. Pour l'utiliser, il est nécessaire d'avoir réalisé deux étapes préalables : - télécharger le document .xlsm de la [plateforme "MonÉvaluation"](https://monevaluation.hceres.fr/hal), - renseigner la seconde feuille du tableur avec les données "locales" relatives au personnel du laboratoire et ses équipes, - adapter les données du code pour jouer le document computationnel sur vos propres données, notamment le chemin du document source, le nom du laboratoire et sa structuration en équipes ou encore certains intitulés de colonnes du fichier .xlsm etc. Ce document constitue la sources des opérations réalisées dans cette partie du document. Au moment de l'édition, ce document est daté du `r format(Sys.time(), "%A %e %B %Y")`.:::### Personnel de recherche de l'UMR IDEES (2020-2026)Un extrait de la liste du personnel de recherche, permanent ou contractuel, par axe, connu sur l'archive HAL est donné dans la table ci-dessous. ```{r personnel-equipes , eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}# lire un document MS Excelrequire(readxl)require(tidyverse)require(kableExtra)source <-"./data/HAL-PRODUCTION-97036_v10022026.xlsm"unitname <-"IDEES UMR CNRS 6266"# création de documents intermédiaires & dossiers associésmap(c("data", "figures", "tables", "stats"), dir.create)# collecte et inscription des données relatives aux équipesstaff <-read_excel(source, sheet =2, skip =11)staff <- staff[, 1:3] %>%set_names(slice(.,1)) %>%slice(-1) %>%mutate(statut ="permanent") %>%bind_rows(staff[, 5:7] %>%set_names(slice(.,1)) %>%slice(-1) %>%mutate(statut ="doctorant")) %>%rename(equipe =`Nom de l'équipe interne`) %>%drop_na()# écriture des données dans le fichierwrite_tsv(staff, "data/staff.tsv")# enregistrement des tablesrequire(webshot2)#- extrait en pngtbl_staff <- staff[sample(nrow(staff),15),] %>%select(-statut) %>%kbl(col.names =NULL, caption ="Table 1 : Extrait aléatoire de la liste des membres de l'UMR et leur affectation thématique.") %>%add_header_above(c("Nom", "Prénom","Axe principal")) %>%kable_styling(full_width = T)tbl_staff %>%save_kable("tables/extrait_staff.png")#- ensemble en pdf imprimablestaff[order(staff$Nom),] %>%select(-statut) %>%kbl(col.names =NULL, longtable = T, booktabs = T) %>%add_header_above(c("Nom", "Prénom","Axe principal")) %>%# kable_classic(full_width = F) %>%kable_styling(latex_options =c("repeat_header")) %>%# column_spec(1) %>% save_kable("tables/total_staff.pdf")````r tbl_staff`### Sélection de types de documentsParmi l'ensemble des productions scientifiques (voir le tableau [-@tbl-doctype] dans la note [-@nte-corpus]), l'étude limite le corpus des publications aux types suivants : article à comité de lecture, conférence, actes de colloques, numéro spécial de revue, ouvrage, chapitre d'ouvrage. D'autres types peuvent être pris en compte, le cas échéant.```{r documents-equipes , eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}require(readxl)require(tidyverse)require(kableExtra)# collecte de la liste des ACLarticle <-read_excel(source, sheet =3, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de l'article`, `Nom de la revue`, `Revue à comité de lecture`) %>%# mutate(type = "article", audience = NA, publisher = NA) %>%mutate(type ="article") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`, TI =`Titre de l'article`,SO =`Nom de la revue`,peereviewed =`Revue à comité de lecture`)# collecte de la liste des communicationsconf <-read_excel(source, sheet =4, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la communication`, `Titre du congrès`, Audience) %>%# mutate(type = "conf", peereviewed = NA, publisher = NA) %>%mutate(type ="conf") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la communication`,SO =`Titre du congrès`,audience = Audience) %>%drop_na(AU)# collecte de la liste des actesactes <-read_excel(source, sheet =6, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la publication`, `Titre du volume`) %>%# mutate(type = "actes", peereviewed = NA, publisher = NA, audience = NA) %>%mutate(type ="actes") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la publication`,SO =`Titre du volume`)# collecte de la liste des numéros spéciauxnspecial <-read_excel(source, sheet =7, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de la publication`, `Titre du volume`) %>%# mutate(type = "nspecial", peereviewed = NA, publisher = NA, audience = NA) %>%mutate(type ="nspecial") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de la publication`,SO =`Titre du volume`)# collecte de la liste des ouvragesbook <-read_excel(source, sheet =8, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre de l'ouvrage`, Editeur) %>%# mutate(type = "book", SO = NA, peereviewed = NA, audience = NA) %>%mutate(type ="book") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre de l'ouvrage`, publisher = Editeur)# collecte de la liste des chapitres d'ouvrageschapter <-read_excel(source, sheet =9, skip =1, col_names =TRUE) %>%select(Auteurs, Année,`Affiliation institutionnelle des co-auteurs`,`Equipes`,Langue,`Lien DOI`,`Lien HAL`,`Titre du chapitre dʹouvrage`, `Titre de l'ouvrage`, Editeur) %>%# mutate(type = "chapter", peereviewed = NA, audience = NA) %>%mutate(type ="chapter") %>%rename(AU = Auteurs, PY = Année,AD =`Affiliation institutionnelle des co-auteurs`,equipe =`Equipes`,langue = Langue,DOI =`Lien DOI`,halid =`Lien HAL`,TI =`Titre du chapitre dʹouvrage`,SO =`Titre de l'ouvrage`, publisher = Editeur)# inscriptions de la liste des documents sélectionnéslibrary(purrr)# fusion des listespub <-bind_rows(actes, article, book, chapter, conf)ncorr <-is.na(pub$equipe) %>%sum(na.rm =TRUE)npub <-nrow(pub)# inscription des données write_tsv(pub, "data/umr_selection.tsv")# production des tables et création de fichiers imagesrequire(webshot2)#- extrait pngtbl_pub <- pub[sample(nrow(pub),15),] %>%select(PY,AU,TI,equipe,halid) %>%kbl(col.names =NULL, caption ="Table 2 : Extrait aléatoire de la liste des documents issu de la production scientifique de l'UMR, précisant l'année de publication, les auteur⋅ices, le titre, l'axe thématique et le n°HAL de la notice HAL.") %>%add_header_above(c("Année", "Auteur/trices","Titre","Axes", "n°HAL")) %>%kable_styling(full_width = T) tbl_pub %>%save_kable("tables/extrait_pub.png")#- ensemble des données en pdf imprimablepub[order(pub$AU),] %>%select(PY,AU,TI,equipe,halid) %>%kbl(col.names =NULL, longtable = T, booktabs = T) %>%add_header_above(c("Année", "Auteur/trices","Titre","Axes", "n°HAL")) %>%# kable_classic(full_width = F) %>%kable_styling(latex_options =c("repeat_header")) %>%# column_spec(1) %>% save_kable("tables/total_pub.pdf")```Au sein du corpus, `r round(ncorr/npub*100,2)`% des notices (soit `r paste(ncorr)` notices) semblent n'être pas associées aux membres du laboratoire attachés à ses axes : des corrections manuelles sont nécessaires (inversion nom/prénom, faux positif etc.). `r tbl_pub`## Premiers éléments d'analyse des données collectées par la méthode indirecte### Types de documents retenus pour l'analyse```{r types-documents, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}library(tidyverse)# selection des documents avec peereviewpub <-read_tsv("data/umr_selection.tsv") %>%filter(! peereviewed %in%"N") %>%rowid_to_column("ID")# inscription des classes type de document et de leur populationpub %>%count(type) %>%arrange(-n) %>%write_tsv("stats/type.tsv") ``````{r plot-types-documents, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}require(readr)require(ggplot2)type_pub <-read_tsv("stats/type.tsv")ggplot(type_pub, aes(x = type, y = n)) +geom_bar(stat ="identity",fill =c("#66a61e","#e7298a","#7570b3","#d95f02","#1b9e77"))+xlab("Type de documents") +ylab("Nombre de documents") +labs(caption ="Figure 4: Représentation du nombre de documents du corpus par type") +theme_minimal() +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969")) # +# theme_minimal()ggsave("figures/type.png")```### Pratiques de publications des équipes : _co-authoring_```{r auteurices-equipes, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}library(tidyverse)library(stringi)# créé une sous-liste des co-auteurices de pub$AUT## motif/pattern de sous catégorisation des auteuricesmotif_aut <-";\\\n|, "split_aut <-function(x) {str_split(x, motif_aut) %>% purrr::map(str_subset, "\\w+")} ## sous catégorisation des co-auteuricespub$aut <- pub$AU %>%split_aut()# créé une sous-liste des équipes de pub$equipe## motif/pattern de sous catégorisation des équipes (il y en a 4)motif_equ <-" ; |; |; |;"split_equ <-function(x) {str_split(x, motif_equ) %>% purrr::map(str_subset, "\\w+")} ## sous catégorisation des équipespub$equ <- pub$equipe %>%split_equ()# créé une colonne du nombre d'auteurices par documentpub <- pub %>% rowwise %>%mutate(nbaut =length(aut)) # nombre de co-auteurices par publication par équipepub %>%unnest(equ) %>%group_by(equ) %>%# groupe par équipesummarise(n =n_distinct(ID), ncoaut =n_distinct(ID[nbaut >1]),mean_coaut =mean(nbaut)) %>%# moyenne nbre auteuricesmutate(coaut = ncoaut/n*100) %>%bind_rows(pub %>%count(equ ="Total", ncoaut =n_distinct(ID[nbaut >1]), mean_coaut =mean(nbaut)) %>%mutate(coaut = ncoaut/n*100)) %>%write_tsv("stats/coaut.tsv")``````{r plot-auteurices-equipes, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(ggplot2)library(scales)require(readr)coaut_equi <-read_tsv("stats/coaut.tsv")# ggplot(coaut_equi, aes(x = equ, y = mean_coaut, fill = coaut)) +# geom_bar(stat = "identity") +# xlab("Équipes") +# ylab("Nombre moyen de co-auteur⋅rices") +# labs(caption = "Figure 5: Nombre de co-auteurs ou autrices par axe des documents issus du corpus (à venir, boîtes à moustaches.") +# theme_minimal() +# guides(fill = guide_legend(title = "% documents\n avec co-auteur⋅\nrices", reverse=T)) +# scale_fill_continuous(high = "#132B43", low = "#56B1F7")coautequ <- pub %>%unnest(equ) %>%select(equ,nbaut)ggplot(coautequ, mapping =aes(x =reorder(equ,nbaut), y = nbaut, fill = equ)) +geom_boxplot(outliers =FALSE) +xlab("Equipes") +ylab("Nombre de co-auteur⋅trices") +labs(caption ="Figure 5: Nombre de co-auteurs ou autrices par axe des documents issus du corpus.") +theme_minimal() +theme(legend.position="none",plot.caption =element_text(hjust =0.5, size =11, colour ="#696969")) ggsave("figures/coaut_equi.png")```### Publications inter-équipes```{r documents-equipes, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = TRUE}# créé une colonne du nombre d'équipes par documentpub <- pub %>% rowwise %>%mutate(nbequipe =length(equ)) # nombre de documents partagés par plus d'une équipepub %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncol =n_distinct(ID[nbequipe >1])) %>%mutate(intereq = ncol/n*100) %>%bind_rows(pub %>%filter(nbaut >1) %>%count(equ ="Total", ncol =n_distinct(ID[nbequipe >1])) %>%mutate(intereq = ncol/n*100)) %>%write_tsv("stats/coequ.tsv")``````{r plot-co-publi-equipes, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(ggplot2)library(knitr)library(kableExtra)co_equ <-read_tsv("stats/coequ.tsv")tbl_co_equ <- co_equ %>%select(equ, intereq) %>%mutate(intereq =round(intereq, 1)) %>%pivot_wider(names_from = equ, values_from = intereq) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 3: Co-production scientifique inter-équipes en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production inter-équipes pour chaque équipe"=4)) %>%kable_styling(full_width = T)tbl_co_equ %>%save_kable("tables/copub_equi.png")````r tbl_co_equ````{r mat-inter-equ-pub, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}library(igraph)el <- pub %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(npub =n_distinct(ID)) %>%unnest_wider(equ, names_sep =" ") %>%rename(i =`equ 1`, j =`equ 2`, k =`equ 3`) %>%drop_na(i) %>%select(i, j, npub) %>%# warning, the only publi involving the 3 teams is removed (??)mutate(j =ifelse(is.na(j), i, j)) %>%drop_na()g <-graph_from_data_frame(el, directed = F, vertices =c("Axe 1","Axe 2","Axe 3","Axe 4"))g <-simplify(g, remove.loops = F, edge.attr.comb ="sum")#mat <- as_adjacency_matrix(g, type = "upper", attr = "npub", sparse = F)mat <-as_adjacency_matrix(g, attr ="npub", sparse = F)mat <- mat/colSums(mat)*100write_rds(mat, "stats/mat.rds")write(data.matrix(mat), "stats/mat.tsv")``````{r , eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}require(gdata)mat <-read_rds("stats/mat.rds")mat <-round(mat, 1)lowerTriangle(mat) <-""mat_co_equ <- mat %>%kbl(booktabs = T, caption ="Table 4: Matrice de répartition de la co-production scientifique (en pourcentage %) entre les équipes à partir des documents du corpus.") %>%add_header_above(c(" ", "Répartition en % de co-production entre les équipes"=4)) %>%kable_styling(full_width = T)mat_co_equ %>%save_kable("tables/mat_copub_equi.png")````r mat_co_equ`### Co-publications avec des extérieur⋅es```{r co-publi-ext, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}require(ggplot2)require(knitr)require(tidyr)# créé une colonne réduite des (nom & initiale prénom) de membres du labostaff <- staff %>%distinct(Nom, Prénom, statut) %>%mutate(initial =str_remove_all(Prénom, "[:lower:]") %>%str_remove_all("\\.") %>%str_remove_all("\\s$"),autc =str_c(str_to_upper(Nom), " ", initial)) %>%distinct(autc, .keep_all = T)# fait une jointure entre la liste des publications & les auteur⋅ices labomatch <- pub %>%unnest(aut) %>%mutate(aut =trimws(aut)) %>%mutate(autc =str_remove_all(aut, "\\.") %>%trimws()) %>%left_join(staff, by ="autc")# ID lignes des auteur∕ices extérieur⋅eshalidautres <- match %>%filter(is.na(Nom)) %>%pull(ID) # ajout d'une colonne ext TRUE si l'auteur⋅ice est extérieurpub <- pub %>%mutate(ext =ifelse(ID %in% halidautres, T, F))# compte la part de co-auteurices extérieur⋅es & le nbre de pub associéespub %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncoext =n_distinct(ID[ext == T])) %>%mutate(coext = ncoext/n*100) %>%bind_rows(pub %>%filter(nbaut >1) %>%count(equ ="Total", ncoext =n_distinct(ID[ext == T])) %>%mutate(coext = ncoext/n*100)) %>%write_tsv("stats/coext.tsv")``````{r plot-co-publi-ext, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(ggplot2)library(knitr)library(kableExtra)coext <-read_tsv("stats/coext.tsv")tbl_co_ext <- coext %>%select(equ, coext) %>%mutate(coext =round(coext, 1)) %>%pivot_wider(names_from = equ, values_from = coext) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 5: Co-production scientifique avec des extérieur⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production avec des extérieur⋅es pour chaque équipe."=4)) %>%kable_styling(full_width = T)tbl_co_ext %>%save_kable("tables/tbl_copub_ext.png")````r tbl_co_ext`### Co-publications avec les doctorant⋅es```{r co-publi-doc, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}library(ggplot2)library(knitr)library(tidyr)# ID lignes des auteur∕ices doctorant⋅esdoct <- match %>%filter(statut =="doctorant") %>%pull(ID) # ajout d'une colonne doct TRUE si l'auteur⋅ice est doctorantpub_co_aut <- pub %>%filter(nbaut >1) %>%mutate(audoct =ifelse(ID %in% doct, T, F))# compte la part de co-auteurices doctorant⋅es & le nbre de pub associéespub_co_aut %>%unnest(equ) %>%filter(nbaut >1) %>%group_by(equ) %>%summarise(n =n_distinct(ID), ncodoct =n_distinct(ID[audoct == T])) %>%mutate(codoct = ncodoct/n*100) %>%bind_rows(pub_co_aut %>%# filter(nbaut > 1) %>%count(equ ="Total", ncodoct =n_distinct(ID[audoct == T])) %>%mutate(codoct = ncodoct/n*100)) %>%write_tsv("stats/codoct.tsv")``````{r plot-co-publi-doct, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(ggplot2)library(knitr)library(kableExtra)codoct <-read_tsv("stats/codoct.tsv")tbl_co_doct <- codoct %>%select(equ, codoct) %>%mutate(codoct =round(codoct, 1)) %>%pivot_wider(names_from = equ, values_from = codoct) %>%select(-c(Total)) %>%mutate(Période ="2020-2026") %>%relocate(Période, 1) %>%kbl(booktabs = T, caption ="Table 6: Co-production scientifique avec les doctorant⋅es en pourcentage (%) pour chaque équipe à partir des documents du corpus.") %>%add_header_above(c(" ", "Pourcentage (%) de co-production avec des doctorant⋅es"=4)) %>%kable_styling(full_width = F)tbl_co_doct %>%save_kable("tables/tbl_copub_doct.png")````r tbl_co_doct`### Langues de publication```{r lang-publi, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}# sélectionner la variable "langue de publication", puis mesurer le nombre ainsi que le pourcentage d'articles par langue et par périodelang <- pub %>%unnest(equ) %>%mutate(langue =str_to_lower(langue)) %>%# mutate(langue = ifelse(langue %in% "anglais, espagnol", "espagnol", langue)) %>%filter(langue %in%c("anglais", "français", "espagnol")) %>%group_by(equ, langue) %>%# grouper les données par période et par langue de publication# créer un nouveau tableau indiquant le nombre d'articles par equipe et par languesummarise(n =n()) %>%mutate(prct =round(n/sum(n)*100, 1)) %>%# ajouter une colonne avec le % d'articles par langue à chaque equipepivot_wider(names_from = equ, values_from =c(n, prct)) %>%# transposer le tableau en largeurmutate(across(everything(), ~replace_na(.x, 0))) %>%# remplacer les valeurs manquantes par des zerosmutate(total_nb =rowSums(across(starts_with("n")))) %>%# ajouter une colonne avec le total des 3 equipemutate(total_prct =round(total_nb/sum(total_nb)*100, 1)) %>%# ajouter une colonne avec le % du totalarrange(-total_nb) %>%relocate(`prct_Axe 1`, .before =3) %>%# modifier la position de la colonne prct_p1relocate(`prct_Axe 2`, .before =5) %>%# modifier la position de la colonne prct_p2 etcrelocate(`prct_Axe 3`, .before =7)write_tsv(lang, "stats/lang.tsv")``````{r table-lang-publi, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}lang <-read_tsv("stats/lang.tsv")tbl_langues <- lang %>%bind_rows(summarise(., # ajouter les totaux par colonneacross(where(is.numeric), \(x) sum(x)), # faire le total pour les colonnes numériquesacross(where(is.character), ~"Total")) %>%# écrire "Total" dans la première colonnemutate(across(contains("prct"), round, 1))) %>%# arrondir les nombres obtenus pour les %kbl(booktabs = T, caption ="Table 7: Répartition par langues (en nombre et en %) de la production scientifique pour chaque équipe à partir des documents du corpus.", col.names =NULL) %>%# représenter le contenu du tableau sauf les entêtes de colonnes# ajouter une première entête de colonne pour chacune des 9 colonnes du tableauadd_header_above(c("Langue", rep(c("Nb", "%"), 5))) %>%# ajouter une seconde entête surplombant la première, indiquant les 3 périodes et la partie Totaladd_header_above(c(" ", "Axe 1"=2, "Axe 2"=2, "Axe 3"=2, "Axe 4"=2, "Total"=2)) %>%# ajouter une troisième entête générale précisant le contenu d'ensemble du tableauadd_header_above(c(" ", "Répartition par équipe des langues de publication et communication par équipe."=10)) %>%kable_styling(full_width = F) %>%# choisir l'apparence du tableau et la policerow_spec(dim(lang)[1]+1, bold = T) %>%# mettre en gras la dernière ligne (totaux en ligne)column_spec(c(3, 5, 7, 9, 11), italic = T)tbl_langues %>%save_kable("tables/tbl_langues_pub.png")````r tbl_langues`### Graphe des revues & équipes```{r revues-equipes , eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE, output = FALSE}# collecte des revues par équipebip <- pub %>%filter(type %in%"article") %>%unnest(equ) %>%group_by(halid) %>%mutate(id =paste0("A", cur_group_id())) %>%ungroup() %>%distinct(id, SO, equ)# revues les plus fréquencestop <- bip %>%group_by(SO) %>%summarise(n =n_distinct(id)) %>%arrange(-n) %>%filter(n >3) %>%# & ! SO %in% "The Conversation"pull(SO)# association revues vs équipesbip <- bip %>%filter(SO %in% top) %>%distinct(equ, SO)# tableau équipe intermédiaireattr <- bip %>%distinct(equ) %>%rename(node = equ) %>%mutate(type ="equipe") # tableau des revuesso <-distinct(bip, SO) %>%mutate(type ="journal") %>%rename(node = SO)# inscriptionwrite_tsv(so, "data/so_rev.tsv")``````{r graph-revues-equipes, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}# construction des noeudsrequire(dplyr)require(stringr)so <-read_tsv("data/so_rev.tsv")v <-bind_rows(attr, so) %>%mutate(col =case_when(node %in%"Axe 1"~"forestgreen", node %in%"Axe 2"~"blue", node %in%"Axe 3"~"purple", node %in%"Axe 4"~"gold",TRUE~"grey"))# construction des classesbipi <- bip %>%left_join(so, by =c("SO"="node")) %>%distinct(SO, equ, type) %>%relocate(SO, 1)# construction des relationsv <-distinct(v, node, type, col)# construction du grapheslibrary(igraph)g <-graph_from_data_frame(bipi, directed = F, vertices = v)# symboliser les évènements par des carrés et les individus par des cerclesV(g)[V(g)$type %in%"journal"]$shape <-"square"V(g)[!V(g)$type %in%"journal"]$shape <-"circle"# choisir deux gammes de couleur pour bien distinguer les deux ensembles de sommetsV(g)$color <- v$col[match(V(g)$name, v$node)]V(g)$label <-ifelse(V(g)$shape %in%"square", str_trunc(V(g)$name, 14), NA)l <-layout_with_fr(g)# library(ggplot2)library(tidygraph)library(ggraph)g %>%ggraph(layout ="fr") +geom_edge_link(edge_colour ="grey") +geom_node_point(aes(filter = type %in%"journal"), show.legend = F, shape =21, fill ="red", stroke =0.2) +geom_node_point(aes(filter =! type %in%"journal", size =degree(g), fill = name), show.legend = F, shape =22, stroke =0.2) +geom_node_text(aes(label =ifelse(type %in%"journal", str_trunc(name, 25), name), fontface =ifelse(! type %in%"journal", "bold", "plain"),size =ifelse(! type %in%"journal", ifelse(degree(g) >=5, 11,8),6)),# size = ifelse(degree(g) >= 5, 7, 6)), colour ="black", repel = T, show.legend = F) +# size = ifelse(degree(g) >= 5, 7, 6)), colour = "black", repel = T, show.legend = F) + # , repel = TRUE, min.segment.length = Inf, max.overlaps = Inftheme_void() +scale_size(guide="none") +labs(fill =c("Equipe"),# title = "Revues à comité de lecture privilégiées par équipe",caption ="Figure 6: Revues dans lesquelles au moins 3 articles ont été publiés entre 2020 et 2026") +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969")) ```## Première synthèse> `r type_pub %>% filter(type %in% "article") %>% pull(n)` articles dans des revues ACL ont été publiés entre 2020 et 2026. > Les publications à plus d'un⋅e auteur⋅rice représentent `r round(coaut_equi %>% filter(equ %in% "Total") %>% pull(coaut), 1)`% des publications. Publier seul⋅e est donc une pratique très minoritaire pour les équipes des axes 1 et 2, resp. `r round(coaut_equi %>% filter(equ %in% "Axe 1") %>% summarise(n = (n - ncoaut)*100/n),1)`% et `r round(coaut_equi %>% filter(equ %in% "Axe 2") %>% summarise(n = (n - ncoaut)*100/n),1)`% des publications, elle est partagée au sein des équipes des axes 3 et 4, resp. `r round(coaut_equi %>% filter(equ %in% "Axe 3") %>% summarise(n = (n - ncoaut)*100/n),1)`% et `r round(coaut_equi %>% filter(equ %in% "Axe 4") %>% summarise(n = (n - ncoaut)*100/n),1)`%.> Parmi les co-publications, `r round(coext %>% filter(equ %in% "Total") %>% pull(coext), 1)`% associent au moins un⋅e auteur⋅rice extérieur⋅e à l’UMR IDEES et `r round(codoct %>% filter(equ %in% "Total") %>% pull(codoct), 1)`% associent au moins un⋅e doctorant⋅e. > `r lang %>% filter(langue %in% "anglais") %>% pull(total_prct)`% des publications sont en anglais. ## Éléments critiquesCette méthode de collecte des données de production scientifique du laboratoire est centrée sur le relevé de notices hal renseignées et rattachées à l'UMR IDEES (voir figure [-@sec-schema-doc]) exploitant une relation de type `notice de document (halId) -> laboratoire (structure_t)` au sein d'un dispositif fermé. La suite de l'étude propose la construction d'un dispositif ouvert mobilisant notamment l'API HAL. Elle s'intéresse en particulier aux auteur⋅rices scientfiiques et leur rôle dans les notices d'oeuvres issues de la production scientifique.