Le seconde est la collecte directe des données HAL au moyen de l’interface de programmation (API, voir Section 3.2.1).
3.1 D’autres plateformes de sources de données
Plusieurs projets documentent le paysage de l’enseignement supérieur et de la recherche (voir #dataESR). Notamment, une vue directe des données accessibles pour l’UMR IDEES est donnée sur la plateforme scanR du ministère, avec plusieurs visualisations.
Figure 6 : Visualisation interactive de la plateforme “ScanR” de consultation des données de publications de l’ESR, issu d’un projet démarré en 2022 (Bracco et al. (2022)). Le filtre utilisé limite la recherche à l’a structure d’affiliation des auteur⋅ices (Identité et différenciation de l’espace, de l’environnement et des sociétés) pour la période 2020-2025. Les visualisations proposées sont une table listant les documents, un histogramme ou encore un diagramme à barre. Les bases de données et leurs structures sont accessibles en ligne.
Une étude fondée sur l’appartenance à l’institution Université Grenoble-Alpes montre la variation des quantités de publications attachées entre diverses sources bibliographiques allant du simple au double. Celles-ci sont notamment dépendantes de pratiques hétérogènes dans le domaine de l’information scientifique et technique et l’absence d’entente générale sur les modalités de citation des affiliations des auteurs ou autrices d’articles ou de productions scientifiques plus généralement.
Comprendre le problème des affiliations, c’est comprendre les différentes répercussions que peut avoir une simple ligne de texte dans l’écosystème des productions scientifiques. En somme, il n’est pas facile d’imaginer qu’une simple ligne de texte puisse avoir autant de conséquences. (Larrieu, Boczon, and Beau-Reder (2024))
Par exemple, les données résultant de requêtes simples sur les plateformes de références donnent des résultats très hétérogènes, pour la période de bilan quadriennal 2020-2025 de l’UMR IDEES (voir Table 3.1)
Table 3.1: Nombre de publications rattachées à l’UMR CNRS 6266 IDEES sur plusieurs aggrégateurs de données académiques pour la période 2020-2025 (sauf IdRef, qui propose par ailleurs d’identifier les membres de la structure et en compte 82)
Fondées sur les notices des publications, la base de données HAL ne lie pas de manière exploitable - c’est à dire à partir d’une requête simple, les auteur⋅rices et leurs structures d’affiliation, ce qui est visible dans cet exemple de requête :
Figure 7 : Affichage du résultat d’une requête sur l’API Hal fondée sur l’identifiant structId_i:97036 de l’UMR IDEES.
3.2 Identifiants chercheur / chercheuse
3.2.1 Collecter les formes auteur⋅ices et Idhal de l’UMR IDEES
Dans le cas de l’API HAL, plusieurs référentiels permettent de collecter des données partielles. Pour pallier en partie à la complexité structurelle d’accès aux données, une modalité d’interrogation comporte des facettes qui aggrègent les données.
Ici, il s’agit de collecter la liste des auteur⋅ices rattaché⋅es à l’UMR IDEES, qui, selon la plateforme HAL (et ses diverses collections), prend la forme du préfixe d’une facette du champ structHasAuthIdHal_fs, auquel est adjoint le nom prénom et l’identifiant HAL (Idhal), s’il existe au sein des métadonnées de la notice, de l’auteur⋅ice.
En savoir plus
Code
library(httr2)library(dplyr)library(knitr)library(DT)# URL de l'APIreq_root ="https://api.archives-ouvertes.fr/search/"# Champs et facettes interrogéesdf <-request(req_root) %>%req_url_query(q ="*",rows =0,facet ="true",facet.field ="structHasAuthIdHal_fs",facet.prefix =97036,facet.limit =-1,wt ="json") %>%req_perform() %>%resp_body_json()# Nombre de lignes de la facette de la sortie jsondg <- df$facet_counts$facet_fields$structHasAuthIdHal_fs %>%unlist()dg_auth <-tibble(auth = dg[c(seq(1, length(dg), 2))]) nb_auth <-length(dg_auth$auth)# Nom des auteur⋅ices, idhal et sans idhaldg_auth <- dg_auth %>%mutate(nom =gsub(pattern =".*JoinSep_.*FacetSep_(.*) .*",replacement ="\\1", auth) %>%tolower() %>%iconv(to='ASCII//TRANSLIT')) %>%mutate(prenom =gsub(pattern =".*JoinSep_.*FacetSep_.* (.*)",replacement ="\\1", auth) %>%tolower() %>%iconv(to='ASCII//TRANSLIT')) %>%mutate(id_hal =gsub(pattern =".*JoinSep_(.*)_FacetSep_.*",replacement ="\\1", auth)) %>%mutate(no_idhal =grepl(pattern ="__",auth))noidhal <- dg_auth %>% dplyr::select(-auth, -id_hal) %>%distinct() %>%summarise(.by =c("nom","prenom"),val=all(no_idhal))idhal <- dg_auth %>% dplyr::select(-auth, -no_idhal) %>%filter(id_hal !="")#idhal <- dg_auth %>% dplyr::select(-auth) %>% distinct() %>% group_by(nom, prenom) %>% summarise(idhal=)# Nombre d'auteur⋅ices disposant d'un Idhal#dg_auth <- mutate(no_idhal = grepl(pattern = "__",dg_auth$auth),dg_auth)#nb_auth_idhal <- dg_auth[dg_auth$no_idhal == FALSE,] |> count()dg_auth <- dg_auth %>%left_join(noidhal, by =c("nom","prenom"))dg_auth <- dg_auth %>%left_join(idhal, by =c("nom","prenom"))
Par exemple, les données auteur⋅ices collectées via l’API HAL (voir ci-dessus) prennent la forme suivante :
97036_FacetSep_Identité et Différenciation de l’Espace, de l’Environnement et des Sociétés_JoinSep_{authIdHal_s}_FacetSep_{authFullName_s}
où
- 97036 est le préfixe de la facette identifiant l’UMR IDEES avec son intitulé,
- en jointure JoinSep avec
- l’Idhal authIdHal_s,
- dont une facette authFullName_s est le nom prénom etc.
Ainsi le nombre de formes auteur⋅rices identifiées (comptant les duplicata comme John Smith et J. Smith), publiant en étant rattaché⋅es à l’UMR IDEES, est de 458. Parmi les auteur⋅ices, environ 165 disposent d’un Idhal, 212 n’en disposent pas.
Accéder au tableau récapitulatif de formes auteur⋅ices avec ou sans idhal
Table : évaluation des formes auteur⋅rices actuelles pour les membres passés ou actuels de l’UMR IDEES.
Note
Afin de couvrir au mieux les productions scientifiques au sein des équipes, il est nécessaire de renseigner au mieux le profil HAL et de “rapatrier” sur l’Idhal, une fois créé, les documents déposés par des tiers sur HAL ou ailleurs. Un pas à pas est accessible (vers la fonctionnalité dédiée de la plateforme HAL, pour choisir les notices pertinentes.)
La dynamique temporelle et spatiale des activités scientifiques à la source de la production de ces données nécessite une mise à jour constante de masses considérables de données de provenances multiples (saisies semi-automatiques des revues, saisies manuelles directes ou indirectes, modérations, curation etc.). L’alignement de l’Idhal des chercheurs et chercheuses avec les identifiants et référentiels pour l’ESR , ou ceux internationaux comme Orcid, permet notamment de moissonner une information scientifique et technique moins bruitée et plus exhaustive.
3.2.2 Étendre la visibilité internationale : Idhal & Orcid
Outre l’identifiant Idhal, d’autres identifiants associés aux auteur⋅rices scientifiques, dits “identifiant chercheur”, permettent d’augmenter la visibilité de la production scientifique dans les systèmes d’information scientifique à l’internationale. Ici, il s’agit de connaître la part de membres de l’UMR IDEES ayant un ORCID rattaché à leur Idhal dans l’archive HAL.
La création d’un compte ORCID permet à chaque auteur⋅rice de publications scientifiques de disposer d’un identifiant unique et pérenne pour référencer l’ensemble de ses travaux. L’identifiant ORCID résout ainsi les ambiguïtés liées au signalement des auteur⋅rices et regroupe leurs publications quelle que soit la plateforme de diffusion utilisée.
Ainsi le nombre d’auteur⋅rices identifiées disposant d’un Idhal et d’un identifiant ORCID dans HAL, est de 114.
Accéder au tableau récapitulatif de identifiants auteur⋅ices avec idhal et ORCID déclaré dans HAL
Table : évaluation des identifiants connus dans HAL (idhal & ORCID) des auteur⋅rices actuels pour les membres passés ou actuels de l’UMR IDEES.
Note
ORCID, qui signifie Open Researcher and Contributor ID, est une organisation mondiale à but non lucratif financée par les frais de ses 1492 organisations membres à l’international, 67 en France dont les universités de Normandie.
Depuis une page intitulée “Transfert de HAL vers ORCID”, il est possible de compléter le profil ORCID avec des publications déposées dans HAL, selon le souhait de chacun⋅e. Il est nécessaire auparavant de créer un identifiant sur la plateforme .
L'objet suivant est masqué depuis 'package:jqr':
contains
Code
require(stringr)
Le chargement a nécessité le package : stringr
Code
require(readr)
Le chargement a nécessité le package : readr
Code
require(tibble)
Le chargement a nécessité le package : tibble
Code
# URL de l'APIreq_root ="https://api.archives-ouvertes.fr/search/"# Champs et facettes interrogéesdf <-request(req_root) %>%req_url_query(q ="*",fq ="producedDateY_i:[2020 TO 2026]",rows =0,facet ="true",facet.field ="structHasAuthIdHal_fs",facet.prefix =97036,facet.limit =-1,wt ="json") %>%req_perform() %>%resp_body_json()# df_1 <- request(req_root) %>% # req_url_query(# q = "(structId_i:(97036))",# fl = "# producedDateY_i,# authIdHalFullName_fs,# structHasAuthIdHal_fs,# halId_s,doiId_s,# docType_s,# language_s,# fileMain_s,# abstract_s,# keyword_s,# citationFull_s,# citationRef_s,# journalTitleAbbr_s# ",# fq ="producedDateY_i:[2020 TO 2026]",# rows = "5000",# wt = "json") |> # req_perform() |> # resp_body_json() df_1 <-request(req_root) %>%req_url_query(q ="(structId_i:(97036))",fl =" producedDateY_i, authIdHalFullName_fs, halId_s,doiId_s, docType_s, language_s, journalTitleAbbr_s ",fq ="producedDateY_i:[2020 TO 2026]",rows ="5000",wt ="json") |>req_perform() |>resp_body_json() # normalisation des données auteur⋅ices## motif/pattern de sous catégorisation des auteuricesmotif_aut <-".*FacetSep_"motif_idhal <-"_FacetSep.*"## aplatissement des co-auteuricesdg <-toJSON(df_1$response$docs) |>fromJSON(, simplifyDataFrame =TRUE) |>rowid_to_column("ID") |>unnest(cols =c(authIdHalFullName_fs,halId_s))## création des champs nomprénom, idhal, nomdg <-mutate(dg, aut =gsub(motif_aut,"\\1",dg$authIdHalFullName_fs[,1]),aut_idhal =gsub(motif_idhal,"\\1",dg$authIdHalFullName_fs[,1]) )dg <-mutate(dg,Nom =trimws(str_to_upper(word(aut,-1)))) personnel <-read_tsv("./data/staff.tsv")
Rows: 194 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (4): Nom, Prénom, equipe, statut
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Code
# fait une jointure entre la liste des publications & les auteur⋅ices labomatch <-tibble( dg %>%left_join(personnel, by ="Nom", relationship ="many-to-many") )# inscription des données #write_tsv(match, "data/umr_api_hal.tsv", )
3.3 Premiers éléments d’analyse des données collectées par la méthode directe
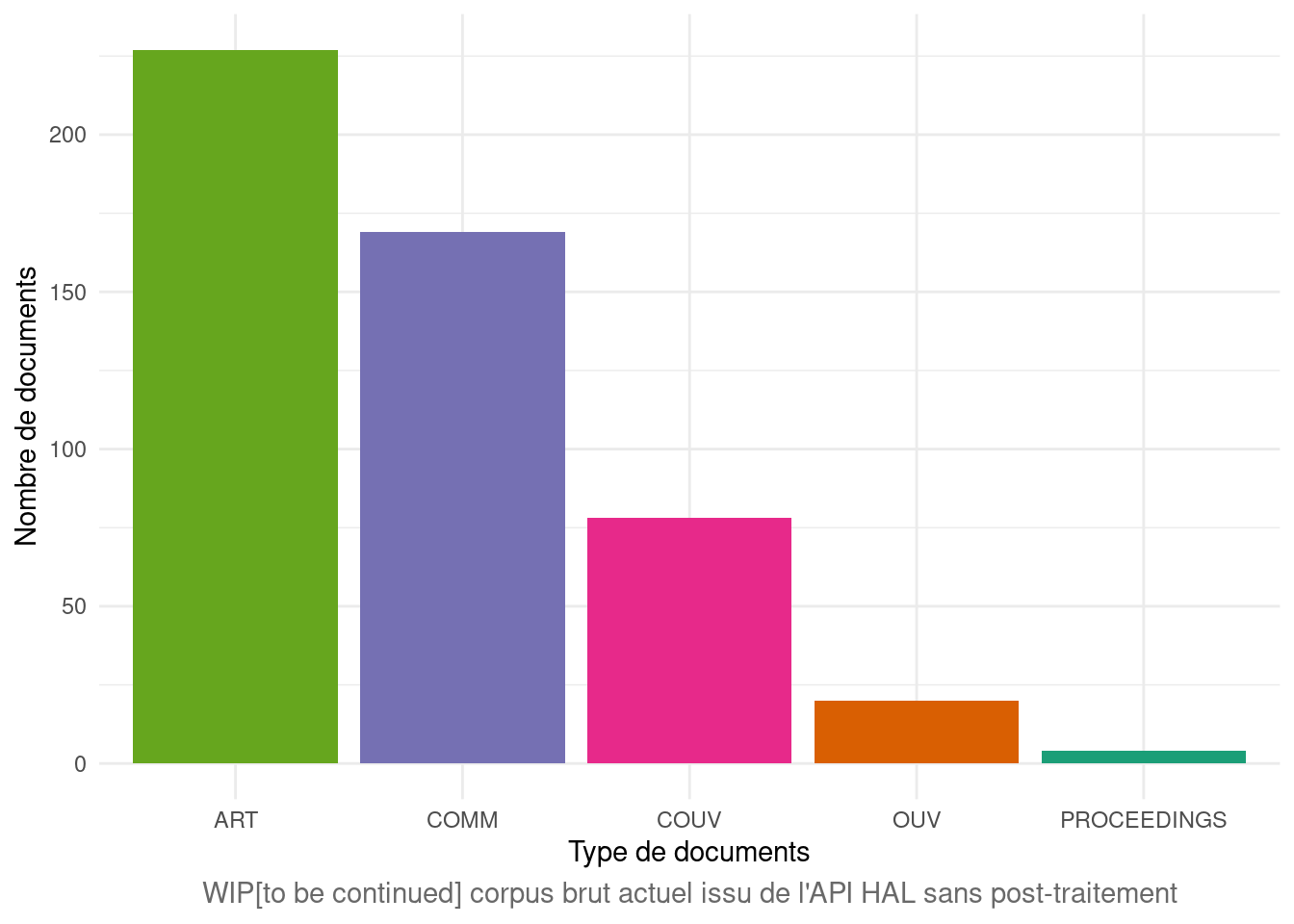
3.3.1 Types de documents retenus pour l’analyse
Code
library(tidyverse)type_pub_halapi <- match %>%mutate(type = docType_s)type_pub_halapi <- type_pub_halapi %>% dplyr::select(ID,type) %>% dplyr::filter(type ==c("PROCEEDINGS","ART","OUV","COUV","COMM"), ) %>%unique() %>% dplyr::count(type)require(ggplot2)ggplot2::ggplot(type_pub_halapi, aes(x =as.character(type), y = n)) +geom_bar(stat ="identity",fill =c("#66a61e","#e7298a","#7570b3","#d95f02","#1b9e77"))+xlab("Type de documents") +ylab("Nombre de documents") +labs(caption ="WIP[to be continued] corpus brut actuel issu de l'API HAL sans post-traitement") +theme_minimal() +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969"))
Warning: Unknown or uninitialised column: `args`.
Unknown or uninitialised column: `args`.
Code
tmp2$halId_s %in% tmp$halId_s %>%summary()
Mode
logical
Bracco, Laetitia, Anne L’Hôte, Eric Jeangirard, and Didier Torny. 2022. “Extending the Open Monitoring of Open Science.”https://hal.science/hal-03651518.
Larrieu, Maxence, Karolin Boczon, and Joseph Beau-Reder. 2024. “Combien d’identifiants ORCID pour l’UGA ?” Blog du pool d'ingénieurs. GATES Data SHS.
Source Code
```{r}#| label: "common"#| include: FALSEsource("_common.R")```# dataESR {#sec-dataESR}Le seconde est la collecte directe des données HAL au moyen de l'interface de programmation (API, voir Section [-@sec-api-hal]).## D'autres plateformes de sources de donnéesPlusieurs projets documentent le paysage de l'enseignement supérieur et de la recherche (voir [#dataESR](https://data.esr.gouv.fr/FR/)). Notamment, une vue directe des données accessibles pour l'UMR IDEES est donnée sur la plateforme [scanR](https://scanr.enseignementsup-recherche.gouv.fr/) du ministère, avec plusieurs visualisations.<figure><iframe src="https://scanr.enseignementsup-recherche.gouv.fr/search/publications?filters=%257B%2522affiliations.id%2522%253A%257B%2522values%2522%253A%255B%257B%2522value%2522%253A%2522200812294H%2522%252C%2522label%2522%253A%2522Identit%25C3%25A9%2520et%2520diff%25C3%25A9renciation%2520de%2520l%27espace%252C%2520de%2520l%27environnement%2520et%2520des%2520soci%25C3%25A9t%25C3%25A9s%2522%257D%255D%252C%2522type%2522%253A%2522terms%2522%252C%2522operator%2522%253A%2522or%2522%257D%252C%2522year%2522%253A%257B%2522values%2522%253A%255B%257B%2522value%2522%253A2020%257D%252C%257B%2522value%2522%253A2025%257D%255D%252C%2522type%2522%253A%2522range%2522%257D%257D" style="width:100%; height:600px;" title="ScanR"></iframe><figcaption>Figure 6 : Visualisation interactive de la plateforme "ScanR" de consultation des données de publications de l'ESR, issu d'un projet démarré en 2022 (@braccoExtendingOpenMonitoring2022). Le filtre utilisé limite la recherche à l'a structure d'affiliation des auteur⋅ices (Identité et différenciation de l'espace, de l'environnement et des sociétés) pour la période 2020-2025. Les visualisations proposées sont une table listant les documents, un histogramme ou encore un diagramme à barre. Les bases de données et leurs structures sont accessibles [en ligne](https://scanr.enseignementsup-recherche.gouv.fr/docs/overview). </figcaption></figure>Une étude fondée sur l'appartenance à l'institution Université Grenoble-Alpes montre la variation des quantités de publications attachées entre diverses sources bibliographiques allant du simple au double. Celles-ci sont notamment dépendantes de pratiques hétérogènes dans le domaine de l'information scientifique et technique et l'absence d'entente générale sur les modalités de citation des affiliations des auteurs ou autrices d'articles ou de productions scientifiques plus généralement.> Comprendre le problème des affiliations, c’est comprendre les différentes répercussions que peut avoir une simple ligne de texte dans l’écosystème des productions scientifiques. En somme, il n’est pas facile d’imaginer qu’une simple ligne de texte puisse avoir autant de conséquences. (@larrieuCombienDidentifiantsORCID2024)Par exemple, les données résultant de requêtes simples sur les plateformes de références donnent des résultats très hétérogènes, pour la période de bilan quadriennal 2020-2025 de l'UMR IDEES (voir @tbl-A)|Source|Nombre de publications|URL Requête||---|---|---||HAL|1168|[URL](https://hal.science/search/index/?q=UMR+IDEES&rows=30&labStructName_s=Identit%C3%A9+et+Diff%C3%A9renciation+de+l%E2%80%99Espace%2C+de+l%E2%80%99Environnement+et+des+Soci%C3%A9t%C3%A9s&publicationDateY_i=2020+OR+2021+OR+2025+OR+2024+OR+2023+OR+2022)||ScanR|1115|[URL](https://scanr.enseignementsup-recherche.gouv.fr/search/publications?filters=%257B%2522affiliations.id%2522%253A%257B%2522values%2522%253A%255B%257B%2522value%2522%253A%2522200812294H%2522%252C%2522label%2522%253A%2522Identit%25C3%25A9%2520et%2520diff%25C3%25A9renciation%2520de%2520l%27espace%252C%2520de%2520l%27environnement%2520et%2520des%2520soci%25C3%25A9t%25C3%25A9s%2522%257D%255D%252C%2522type%2522%253A%2522terms%2522%252C%2522operator%2522%253A%2522or%2522%257D%252C%2522year%2522%253A%257B%2522values%2522%253A%255B%257B%2522value%2522%253A2020%257D%252C%257B%2522value%2522%253A2025%257D%255D%252C%2522type%2522%253A%2522range%2522%257D%257D)|| IdRef (toute période)|262|[URL](https://www.idref.fr/185082564)||OpenAlex|302|[URL](https://openalex.org/works?page=1&filter=raw_affiliation_strings.search:UMR+IDEES,publication_year:2020-2025)||WebOfScience (fermé) |112 |[URL](https://www.webofscience.com/wos/woscc/summary/cf92cabb-93d6-4730-97b8-f04bc4e929b6-0192158896/relevance/1)||Lens|103|[URL](https://www.lens.org/lens/search/scholar/list?q=UMR%20CNRS%20IDEES%206266&p=0&n=10&s=_score&d=%2B&f=false&e=false&l=en&authorField=author&dateFilterField=publishedYear&orderBy=%2B_score&presentation=false&preview=true&stemmed=true&useAuthorId=false&publishedYear.from=2020&publishedYear.to=2025)|: Nombre de publications rattachées à l'UMR CNRS 6266 IDEES sur plusieurs aggrégateurs de données académiques pour la période 2020-2025 (sauf IdRef, qui propose par ailleurs d'identifier les membres de la structure et en compte 82) {#tbl-A}Fondées sur les notices des publications, la base de données HAL ne lie pas de manière exploitable - c'est à dire à partir d'une requête simple, les auteur⋅rices et leurs structures d'affiliation, ce qui est visible dans cet [exemple de requête](https://api.archives-ouvertes.fr/search/?q=structId_i:97036&fl=authFullName_s,instStructName_s,docType_s,halId_s,title_s&rows=5) : <iframe src="https://api.archives-ouvertes.fr/search/?q=structId_i:97036&fl=authFullName_s,instStructName_s,docType_s,halId_s,title_s&rows=5" width="95%" height="500px" allowfullscreen="true" style="border:1px solid black;padding:5px;margin:5px;"></iframe><figure><figcaption>Figure 7 : Affichage du résultat d'une requête sur l'API Hal fondée sur l'identifiant `structId_i:97036` de l'UMR IDEES.</figcaption></figure>## Identifiants chercheur / chercheuse### Collecter les formes auteur⋅ices et Idhal de l'UMR IDEES {#sec-api-hal}> Dans le cas de l'API HAL, plusieurs référentiels permettent de collecter des données partielles. Pour pallier en partie à la complexité structurelle d'accès aux données, une modalité d'interrogation comporte des facettes qui aggrègent les données.Ici, il s'agit de collecter la liste des auteur⋅ices rattaché⋅es à l'UMR IDEES, qui, selon la plateforme HAL (et ses diverses collections), prend la forme du préfixe d'une facette du champ `structHasAuthIdHal_fs`, auquel est adjoint le nom prénom et l'identifiant HAL (Idhal), s'il existe au sein des métadonnées de la notice, de l'auteur⋅ice.<details><summary>En savoir plus</summary>```{r structHasAuthIdHal, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(httr2)library(dplyr)library(knitr)library(DT)# URL de l'APIreq_root ="https://api.archives-ouvertes.fr/search/"# Champs et facettes interrogéesdf <-request(req_root) %>%req_url_query(q ="*",rows =0,facet ="true",facet.field ="structHasAuthIdHal_fs",facet.prefix =97036,facet.limit =-1,wt ="json") %>%req_perform() %>%resp_body_json()# Nombre de lignes de la facette de la sortie jsondg <- df$facet_counts$facet_fields$structHasAuthIdHal_fs %>%unlist()dg_auth <-tibble(auth = dg[c(seq(1, length(dg), 2))]) nb_auth <-length(dg_auth$auth)# Nom des auteur⋅ices, idhal et sans idhaldg_auth <- dg_auth %>%mutate(nom =gsub(pattern =".*JoinSep_.*FacetSep_(.*) .*",replacement ="\\1", auth) %>%tolower() %>%iconv(to='ASCII//TRANSLIT')) %>%mutate(prenom =gsub(pattern =".*JoinSep_.*FacetSep_.* (.*)",replacement ="\\1", auth) %>%tolower() %>%iconv(to='ASCII//TRANSLIT')) %>%mutate(id_hal =gsub(pattern =".*JoinSep_(.*)_FacetSep_.*",replacement ="\\1", auth)) %>%mutate(no_idhal =grepl(pattern ="__",auth))noidhal <- dg_auth %>% dplyr::select(-auth, -id_hal) %>%distinct() %>%summarise(.by =c("nom","prenom"),val=all(no_idhal))idhal <- dg_auth %>% dplyr::select(-auth, -no_idhal) %>%filter(id_hal !="")#idhal <- dg_auth %>% dplyr::select(-auth) %>% distinct() %>% group_by(nom, prenom) %>% summarise(idhal=)# Nombre d'auteur⋅ices disposant d'un Idhal#dg_auth <- mutate(no_idhal = grepl(pattern = "__",dg_auth$auth),dg_auth)#nb_auth_idhal <- dg_auth[dg_auth$no_idhal == FALSE,] |> count()dg_auth <- dg_auth %>%left_join(noidhal, by =c("nom","prenom"))dg_auth <- dg_auth %>%left_join(idhal, by =c("nom","prenom"))```Par exemple, les données auteur⋅ices collectées via l'API HAL (voir ci-dessus) prennent la forme suivante : `97036_FacetSep_Identité et Différenciation de l’Espace, de l’Environnement et des Sociétés_JoinSep_{authIdHal_s}_FacetSep_{authFullName_s}`où - `97036` est le préfixe de la facette identifiant l'UMR IDEES avec son intitulé, - en jointure `JoinSep` avec - l'Idhal `authIdHal_s`, - dont une facette `authFullName_s` est le nom prénom etc. </details>> Ainsi le **nombre de formes auteur⋅rices identifiées** (comptant les duplicata comme John Smith et J. Smith), publiant en étant rattaché⋅es à l'UMR IDEES, est de `r nb_auth`. Parmi les auteur⋅ices, environ **`r noidhal %>% filter(val == FALSE) %>% count()` disposent d'un Idhal**, `r noidhal %>% filter(val == TRUE) %>% count()` n'en disposent pas.> <img src="/img/OIP.jpeg" height="70px"><details><summary>**Accéder au tableau récapitulatif de formes auteur⋅ices avec ou sans idhal**</summary><figure>`r dg_auth[c("nom","prenom","id_hal.y")] %>% unique() %>% DT::datatable()`<figcaption>Table : évaluation des formes auteur⋅rices actuelles pour les membres passés ou actuels de l'UMR IDEES.</figcaption></figure></details>:::{.callout-note}Afin de couvrir au mieux les productions scientifiques au sein des équipes, il est nécessaire de renseigner au mieux le profil HAL et de "rapatrier" sur l'Idhal, une fois créé, les documents déposés par des tiers sur HAL ou ailleurs. Un [pas à pas](https://sdrive.cnrs.fr/s/pMGA2Wf6rPsamg8) est accessible (vers la fonctionnalité dédiée de la plateforme HAL, pour choisir les notices pertinentes.):::La dynamique temporelle et spatiale des activités scientifiques à la source de la production de ces données nécessite une mise à jour constante de masses considérables de données de provenances multiples (saisies semi-automatiques des revues, saisies manuelles directes ou indirectes, modérations, curation etc.). L'alignement de l'Idhal des chercheurs et chercheuses avec les identifiants et référentiels pour l'ESR [<img src="https://publications-prairial.fr/arabesques/docannexe/image/213/img-1.jpg" height="20px">](https://www.idref.fr/), ou ceux internationaux comme Orcid, permet notamment de moissonner une information scientifique et technique moins bruitée et plus exhaustive.### Étendre la visibilité internationale : Idhal & OrcidOutre l'identifiant Idhal, d'autres identifiants associés aux auteur⋅rices scientifiques, dits "identifiant chercheur", permettent d'augmenter la visibilité de la production scientifique dans les systèmes d'information scientifique à l'internationale. Ici, il s'agit de connaître la part de membres de l'UMR IDEES ayant un ORCID rattaché à leur Idhal dans l'archive HAL.> La création d’un compte ORCID permet à chaque auteur⋅rice de publications scientifiques de disposer d’un identifiant unique et pérenne pour référencer l’ensemble de ses travaux. L’identifiant ORCID résout ainsi les ambiguïtés liées au signalement des auteur⋅rices et regroupe leurs publications quelle que soit la plateforme de diffusion utilisée.<details><summary>En savoir plus</summary>```{r orcidId_s, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(httr2)library(dplyr)library(jsonlite)library(jqr)# URL de l'APIreq_auth ="https://api.archives-ouvertes.fr/ref/author"# balaye id_hal trouvésidHal_s <-list()nidhal <-length(idhal$id_hal)dg_orcid <-list()for (i in1:nidhal) {idHal_s$q <-paste0("idHal_s:",paste0(idhal$id_hal[i]))#idHal_s <- list(q = "idHal_s:raphaelle-krummeich")# Champs et facettes interrogéesdf_orcid <-request(req_auth) %>%req_url_query(!!!idHal_s,fl ="hasCV_bool",fl ="orcidId_s",wt ="json") %>%req_perform() %>%resp_body_json() %>%toJSON() %>% jqr::jq(".[] .docs") %>%fromJSON() %>%unique() %>%cbind(sub(".*:(.*)","\\1",idHal_s$q))ndf <-length(df_orcid)if(ndf ==3) {dg_orcid <- dg_orcid %>%rbind(df_orcid)}}```</details>> Ainsi le **nombre d'auteur⋅rices identifiées** disposant d'un Idhal et d'un identifiant ORCID dans HAL, est de `r nrow(dg_orcid)`. <details><summary>**Accéder au tableau récapitulatif de identifiants auteur⋅ices avec idhal et ORCID déclaré dans HAL**</summary><figure>`r dg_orcid %>% DT::datatable()`<figcaption>Table : évaluation des identifiants connus dans HAL (idhal & ORCID) des auteur⋅rices actuels pour les membres passés ou actuels de l'UMR IDEES.</figcaption></figure></details>:::{.callout-note}ORCID, qui signifie _Open Researcher and Contributor ID_, est une organisation mondiale à but non lucratif financée par les frais de ses 1492 [organisations membres](https://orcid.org/members) à l'international, 67 en France dont les universités de Normandie.Depuis une page intitulée "Transfert de HAL vers ORCID", il est possible de compléter le profil ORCID avec des publications déposées dans HAL, selon le souhait de chacun⋅e. Il est nécessaire auparavant de créer un identifiant [<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/0/06/ORCID_iD.svg/250px-ORCID_iD.svg.png" width="20px">](https://orcid.org/) sur la plateforme [<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/1/14/ORCID_logo.svg/250px-ORCID_logo.svg.png" height="20px">](https://orcid.org/register). :::```{python orcid api}#| echo: false#| eval: false#| output: falseimport osimport requestsimport pandas as pd# Get the directory of the scriptscript_dir = os.getcwd()# TODO collecte nom & prénom avec accent & tolower & générer urls# Define the URLsurls = []urls.append("https://pub.orcid.org/v3.0/csv-search/?q=family-name:'rey-coyrehourcq'+AND+given-names:sébastien")urls.append("https://pub.orcid.org/v3.0/csv-search/?q=family-name:banos+AND+given-names:arnaud")# Define function to download CSVdef download_csv(uri, filename): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3","Accept-Encoding": "gzip, deflate","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Upgrade-Insecure-Requests": "1","DNT": "1","Connection": "close","Content-Type": "text/html" } response = requests.get(uri, headers=headers)if response.status_code ==200:withopen(os.path.join(script_dir, filename), "wb") as f: f.write(response.content)print(f"CSV downloaded from {uri} and saved as {filename}")else:print(f"Failed to download CSV from {uri}")# Download the three CSV filesfor idx, uri inenumerate(urls, start=1): filename =f"ORCID_API_request_{idx}.csv" download_csv(uri, filename)# Define function to merge CSV filesdef merge_csv_files(): csv_files = [fileforfilein os.listdir(script_dir) iffile.endswith('.csv')] dfs = []forfilein csv_files: df = pd.read_csv(os.path.join(script_dir, file)) dfs.append(df) merged_df = pd.concat(dfs, ignore_index=True) merged_df.to_csv(os.path.join(script_dir, 'orcid.csv'), index=False)print("CSV files merged successfully.")merge_csv_files()``````{r}require(httr2)require(dplyr)require(knitr)require(jsonlite)require(tidyr)require(stringr)require(readr)require(tibble)# URL de l'APIreq_root ="https://api.archives-ouvertes.fr/search/"# Champs et facettes interrogéesdf <-request(req_root) %>%req_url_query(q ="*",fq ="producedDateY_i:[2020 TO 2026]",rows =0,facet ="true",facet.field ="structHasAuthIdHal_fs",facet.prefix =97036,facet.limit =-1,wt ="json") %>%req_perform() %>%resp_body_json()# df_1 <- request(req_root) %>% # req_url_query(# q = "(structId_i:(97036))",# fl = "# producedDateY_i,# authIdHalFullName_fs,# structHasAuthIdHal_fs,# halId_s,doiId_s,# docType_s,# language_s,# fileMain_s,# abstract_s,# keyword_s,# citationFull_s,# citationRef_s,# journalTitleAbbr_s# ",# fq ="producedDateY_i:[2020 TO 2026]",# rows = "5000",# wt = "json") |> # req_perform() |> # resp_body_json() df_1 <-request(req_root) %>%req_url_query(q ="(structId_i:(97036))",fl =" producedDateY_i, authIdHalFullName_fs, halId_s,doiId_s, docType_s, language_s, journalTitleAbbr_s ",fq ="producedDateY_i:[2020 TO 2026]",rows ="5000",wt ="json") |>req_perform() |>resp_body_json() # normalisation des données auteur⋅ices## motif/pattern de sous catégorisation des auteuricesmotif_aut <-".*FacetSep_"motif_idhal <-"_FacetSep.*"## aplatissement des co-auteuricesdg <-toJSON(df_1$response$docs) |>fromJSON(, simplifyDataFrame =TRUE) |>rowid_to_column("ID") |>unnest(cols =c(authIdHalFullName_fs,halId_s))## création des champs nomprénom, idhal, nomdg <-mutate(dg, aut =gsub(motif_aut,"\\1",dg$authIdHalFullName_fs[,1]),aut_idhal =gsub(motif_idhal,"\\1",dg$authIdHalFullName_fs[,1]) )dg <-mutate(dg,Nom =trimws(str_to_upper(word(aut,-1)))) personnel <-read_tsv("./data/staff.tsv")# fait une jointure entre la liste des publications & les auteur⋅ices labomatch <-tibble( dg %>%left_join(personnel, by ="Nom", relationship ="many-to-many") )# inscription des données #write_tsv(match, "data/umr_api_hal.tsv", )```## Premiers éléments d'analyse des données collectées par la méthode directe### Types de documents retenus pour l'analyse```{r types-documents-halapi, eval=TRUE, echo=TRUE, warning= FALSE, message = FALSE}library(tidyverse)type_pub_halapi <- match %>%mutate(type = docType_s)type_pub_halapi <- type_pub_halapi %>% dplyr::select(ID,type) %>% dplyr::filter(type ==c("PROCEEDINGS","ART","OUV","COUV","COMM"), ) %>%unique() %>% dplyr::count(type)require(ggplot2)ggplot2::ggplot(type_pub_halapi, aes(x =as.character(type), y = n)) +geom_bar(stat ="identity",fill =c("#66a61e","#e7298a","#7570b3","#d95f02","#1b9e77"))+xlab("Type de documents") +ylab("Nombre de documents") +labs(caption ="WIP[to be continued] corpus brut actuel issu de l'API HAL sans post-traitement") +theme_minimal() +theme(plot.caption =element_text(hjust =0.5, size =11, colour ="#696969")) ```### Comparaison méthodes```{r}tmp <-gsub("https://hal.science/","",article$halid) %>%as.data.frame()colnames(tmp) <-"halId_s"tmp2 <- dg %>%filter(docType_s =="ART") %>%select(halId_s) %>%unique() tmp2$halId_s %in% tmp$halId_s %>%summary()```